はじめに
はじめまして、3月まで新卒エンジニアのカトウです⛄️🌸
【この記事でやること】
何度も訪問しているWebサイトを調べて、内容を要約する
- Google Chromeの検索履歴データベースを使用して、アクセス回数の多いサイトを調べる
- Google Gemini APIを使用して、サイトの内容を要約する
【きっかけ】
入社して1年、何度も同じ検索クエリを打ち込み、何度も同じWebページに訪問していることに気がついています、、、、、、、
検索履歴のデータから、私がどんな内容を覚えられずに何度もサイトにアクセスしているか知れたらいいなと思います!🧠📚
訪問回数が多いサイト調べる
使用するデータ
Google Chromeの検索履歴(SQLiteのデータベースファイル)はローカルに保存されています。
/Users/{ユーザー名}/Library/Application\ Support/Google/Chrome/Default/History
残念ながら、Chromeの検索履歴は過去90日間しか保存されないようです。1年間の振り返りができたらよかったのですが、3ヶ月間の振り返りとなります🍰
visitsテーブルのデータ期間の確認
SELECT MIN(strftime('%Y-%m-%d', (visits.visit_time / 1000000 - 11644473600), 'unixepoch')), MAX(strftime('%Y-%m-%d', (visits.visit_time / 1000000 - 11644473600), 'unixepoch')) FROM visits;
実行結果

データベースの接続
🔐 Chromeを起動している状態だと、データベースがロックされ、操作することができません。

Chromeを終了するか、コピーを使用することで接続することができます。
今回は、新しくディレクトリを用意して、データベースファイルをコピーして使用しました。
カレントディレクトリにコピー
$ cp /Users/{ユーザー名}/Library/Application\ Support/Google/Chrome/Default/History .
✅ Chromeを開いている状態でも、データベースを操作することができるようになりました!
$ sqlite3 History

使用するテーブル
.tableコマンドでテーブルを確認
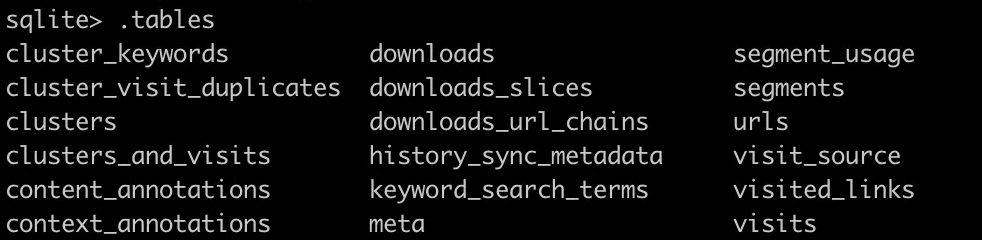
テーブルのカラムを以下コマンドで確認
PRAGMA table_info('テーブル名');
urls: アクセスしたURLのテーブル
主なカラム
| カラム | 内容 |
|---|---|
| id | URLのID |
| url | アクセスしたURL |
| title | Webサイトのタイトル |
| visit_count | URLがアクセスされた回数 |
| last_visit_time | 最後にアクセスした日時 |
urlsテーブルのカラム一覧
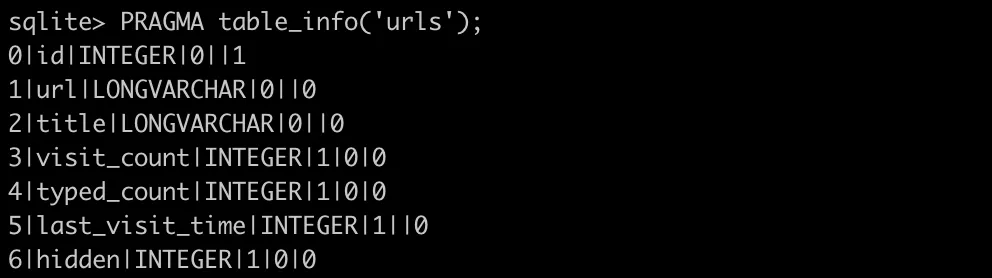
visits: URLのアクセス履歴のテーブル
主なカラム
| カラム | 内容 |
|---|---|
| id | アクセスID |
| url | アクセスされたURLのID(urls.idへの外部キー) |
| visit_time | アクセスした日時 |
| from_visit | アクセス元のアクセスID |
| visit_duration | アクセス時間 |
visitsテーブルのカラム一覧
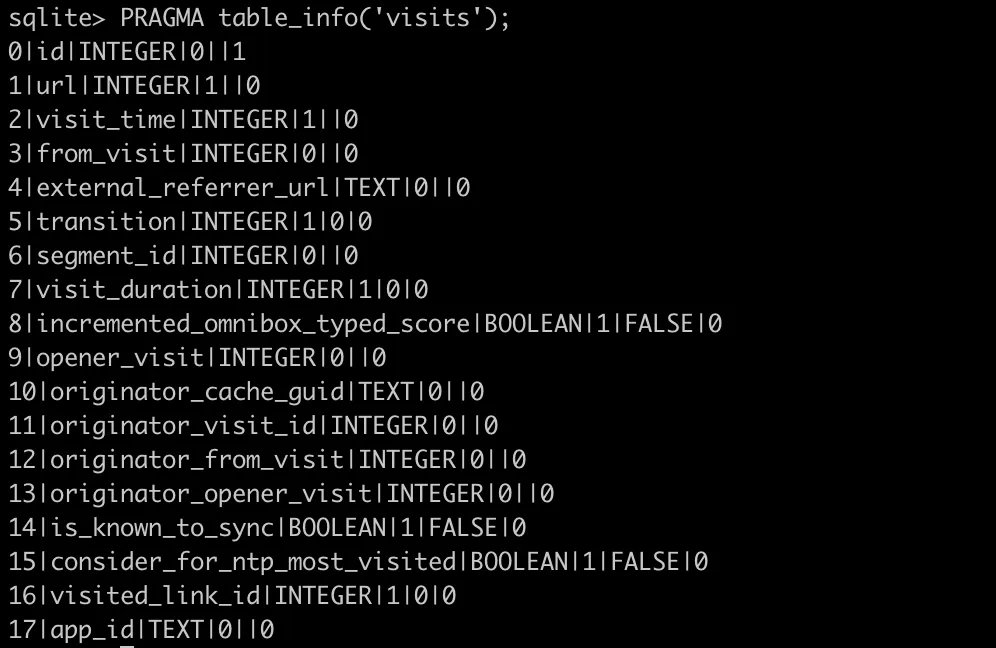
▶️ Googleキーワード検索結果ページからアクセスしたWebサイトのうち、アクセス回数の多いWebサイトを表示します!
ブックマークや、直接リンクを踏んでアクセスしたサイトではなく、検索結果からアクセスしたサイトに限定して調べたいです。
実装
pythonコード
import sqlite3 # 何件取得するか LIMIT = 5 # ブラウザ履歴データベースのパスを指定 DB_PATH = "./History" def get_top_visited_sites(db_path): conn = sqlite3.connect(db_path) cursor = conn.cursor() LIMIT = 5 cursor.execute(""" SELECT urls.title, urls.url, COUNT(visits.id) AS visit_count FROM visits INNER JOIN urls ON visits.url = urls.id WHERE visits.from_visit IN ( SELECT visits.id FROM visits INNER JOIN urls ON visits.url = urls.id WHERE urls.url LIKE '%google.com/search?%' ) GROUP BY urls.id ORDER BY visit_count DESC LIMIT ? """, (LIMIT,)) return cursor.fetchall() def main(): results = get_top_visited_sites(DB_PATH) print(f"\n** Google検索結果からアクセスしたWebサイト上位{LIMIT}件 **\n") for title, url, count in results: print(f"- タイトル: {title}") print(f" URL: {url}") print(f" アクセス回数: {count}回\n") main()
実行結果
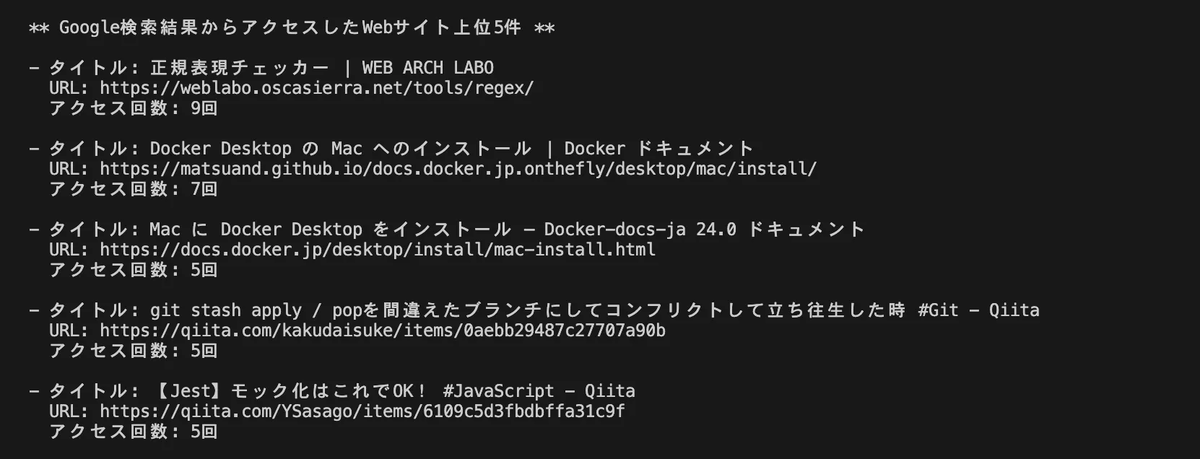
✅ 何度もアクセスしているWebサイトのURLを取得することができました!
もっともアクセスしている、WEB ARCH LABOの正規表現チェッカーは、確かに気に入っていてよく使っています!ブックマークした方がよさそうですね🔖💭
覚えられずに、何度も検索しているだけではないようです。
SQLクエリの説明
- サブクエリ: Google検索結果ページのURLのIDを抽出
SELECT visits.id FROM visits INNER JOIN urls ON visits.url = urls.id WHERE urls.url LIKE '%google.com/search?%'
urlsテーブルとvisitsテーブルを結合アクセスしたURL
urls.urlが "google.com/search?" を含むものを抽出
抽出したURLの
visits.idのリストを取得メインクエリ: 対象のサイトのタイトル、URL、アクセス回数を抽出
SELECT urls.title, urls.url, COUNT(visits.id) AS visit_count FROM visits INNER JOIN urls ON visits.url = urls.id WHERE visits.from_visit IN (サブクエリ) GROUP BY urls.id ORDER BY visit_count DESC LIMIT 5
visitsテーブルとurlsテーブルを結合WHERE visits.from_visit IN (サブクエリ)でサブクエリで取得したGoogle検索結果のURLからアクセスしたURLのみに絞り込むGROUP BY urls.idでURLごとにグループ化ORDER BY visit_count DESCでアクセス回数が多い順にソートLIMITで上位何件まで取得するか指定
⏩ 次に、Google Geminiを使用して取得したURLから、Webサイトの要約をします!
サイトを要約する
Google Gemini APIを使う準備
以下ページの手順通りに進めるだけで、簡単に使用することができました!
実装
Google Chromeの検索履歴データベースから、よくアクセスしているサイトの情報を取得し、タイトルとURLをもとにサイトの内容をGoogle Geminiに要約してもらいます。
pythonコード
import sqlite3 from google import genai # Google Gemini APIのAPIキーを設定 API_KEY = "YOUR_API_KEY" # ブラウザ履歴データベースのパスを指定 DB_PATH = "./History" # 何件取得するか LIMIT = 5 def get_top_visited_sites(db_path): conn = sqlite3.connect(db_path) cursor = conn.cursor() cursor.execute(""" SELECT urls.title, urls.url, COUNT(visits.id) AS visit_count FROM visits INNER JOIN urls ON visits.url = urls.id WHERE visits.from_visit IN ( SELECT visits.id FROM visits INNER JOIN urls ON visits.url = urls.id WHERE urls.url LIKE '%google.com/search?%' ) GROUP BY urls.id ORDER BY visit_count DESC LIMIT ? """, (LIMIT,)) rows = cursor.fetchall() print(f"\n**Google検索結果からアクセスしたWebサイト上位{LIMIT}件**\n") for title, url, count in rows: print(f"\033[42m {title} \033[0m") print(f"URL: {url}") print(f"アクセス回数: {count}回\n") summary = summarize_with_gemini(title, url) print(f"{summary}\n") if conn: conn.close() def summarize_with_gemini(title, url): client = genai.Client(api_key=API_KEY) content = f"{title}({url})のウェブサイトの内容を簡単に要約してください。" response = client.models.generate_content( model='gemini-2.0-flash', contents=content ) return response.text def main(): get_top_visited_sites(DB_PATH) main()
実行結果
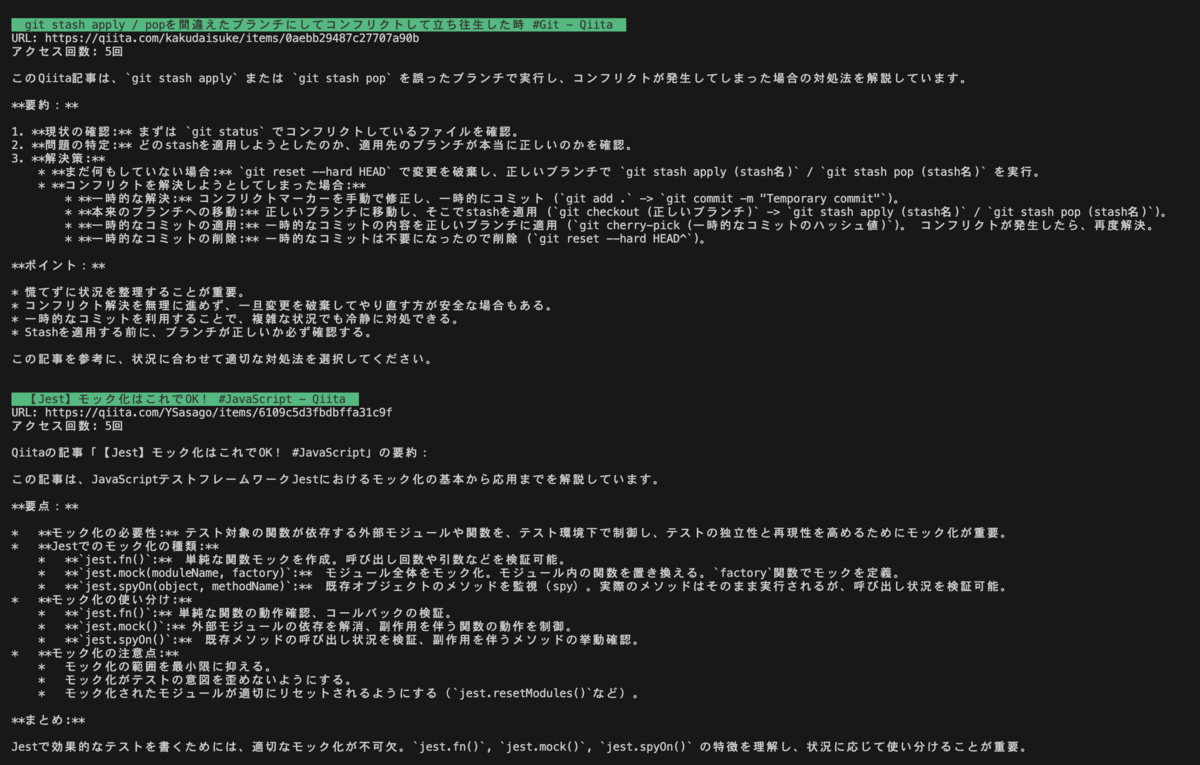
さいごに
【この記事でやりたかったこと】
何度も訪問しているWebサイトを調べて、内容を要約する
【できたこと】
✅ Google Chrome検索履歴から、なんのサイトに何回アクセスしているかわかりました!
✅ Google Gemini APIを使用して、指定したサイトの内容を要約しました!
【できそうなこと】
💡Google Chromeの検索履歴データベースには、アクセスした日時やアクセスしていた時間のデータも保持しています。時間に着目してもおもしろそうです!
【まとめ】
Google検索結果からよくアクセスするサイトがわかったことで、ブックマークで検索の手間を省くことができました!
Google Gemini APIでよくアクセスするサイトを要約することで、検索しなくてもサイトの内容がざっくりわかりました!
ここまで読んでくださり、ありがとうございます!✨
この記事を読んで少しでも興味を持ってくださった方は、ぜひカジュアル面談でお話ししましょう!
iimon採用サイト / Wantedly / Green