
はじめに
iimonでエンジニアをしている腰丸です。ここ最近、業務で生成AIを活用しながら作業をすることが増えてきました。
そこで、これまではあまり積極利用していなかったのですが、MCPサーバーを利用して多少なりとも業務を効率化できないかを調査し、
「serena」と「github」のMCPサーバーを利用することで多少の効果がでた気がするので記事にまとめました。
普段の業務では、copilot Agentを使用しているので、そちらの手順をまとめました。(個人で課金して、claude codeに乗り換えたほうが良い気はしているのですが...)
Serena MCP
設定
uvのインストール
- 好みの方法でuvをインストールします。(自分はasdfを使用しています)
VsCodeの設定
- 「⌘ + shift + p」を押して 「MCP」と入力します。自分の場合は、今回はユーザー設定としてserenaを入れたいので、「MCP: Open User Configration」を選択します
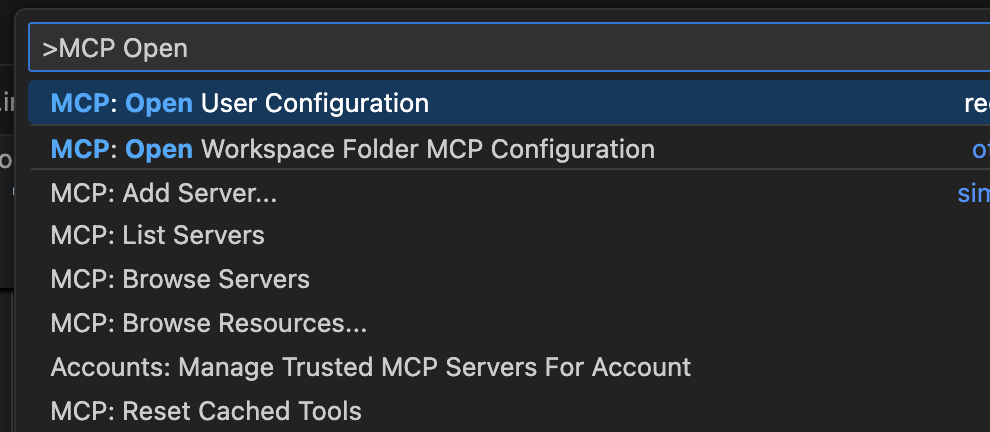
- 下記の内容を記述します。
{ "servers": { "serena": { "type": "stdio", "command": "/Users/{userName}/.asdf/shims/uvx", // uvxのPathを指定します。 "args": [ "--from", "git+https://github.com/oraios/serena", "serena", "start-mcp-server", "--context", "ide-assistant" ] } } }
- 概要
| 項目 | 説明 | 参考リンク |
|---|---|---|
servers |
MCP サーバーの一覧を書く場所です。ここに登録したツールを Copilot が利用できるようになります。 | VS Code Docs: Configure MCP |
"serena" |
サーバーの名前(ID)です。自由につけられますが、今回はツール名に合わせて "serena" にしています。 |
– |
"type": "stdio" |
通信方式を指定します。Serena は CLI プロセスとして起動し、標準入出力(stdio)で VS Code とやりとりします。 | VS Code Docs: Example servers config) |
"command": "/Users/.../uvx" |
起動コマンドです。今回はuvxを使用するのでuvxのパスを指定します。 | uv Docs |
"args" |
command に渡す引数です。ドキュメント通りの内容で記述します。 今回の意味は以下のとおり: • --from git+https://github.com/oraios/serena → Serena を GitHub から取得して実行する• serena start-mcp-server → Serena を MCP サーバーモードで起動する• --context ide-assistant → IDE用モードで起動する(Serena 公式推奨))• --project ${workspaceFolder} → VS Code で開いているワークスペースのルートディレクトリをプロジェクトとして自動指定する(これにより開いているリポジトリが自動でアクティブ化される) |
Serena GitHub README |
serena用のinstructionsファイルを作成する
copilotの設定から、instructionsファイルを作成します。「New Instructions File > .github/instructions / User Data Folder」を選択

- プロンプト例:
--- applyTo: '**' --- # 🧭 プロジェクト全体ルール(全リポ共通) - 解答には可能な限りSerena MCPを使用すること ## 0) Serena MCP — 読み取りとオンボーディングは必須 - 既存コードの理解や参照が必要な場合、**必ず Serena MCP を経由**して読み取ること。 - 例: read_file, list_files, search_symbols, search_text, project_memories - **プロジェクトの分析(オンボーディング)が未実行の場合は、最初の提案時に必ず自動でオンボーディングを実行してから回答する。** - オンボーディングでは、プロジェクトの構成・依存関係・規約を読み込み、その知識を基盤に提案を行うこと。 - プロジェクトの構成や依存が大きく変化したと推測される場合は、再度オンボーディングを実行してから提案する。 - Serena が無効な場合はその旨を伝え、 「Serena経由の読取が無効です。有効化しますか? それとも最小仮説で続行しますか?」 と確認してから続行する。 ## 1) まず文脈を読む 1. Serena でまずリポジトリの構成や規約を確認する - **コーディング規約やフォーマッタの設定ファイル**(例: Linter、Formatter の設定) - **ビルドやテストの設定ファイル**(例: ビルドスクリプト、テスト設定、依存管理ファイル) - **フレームワークや環境設定ファイル**(例: 言語ごとの設定、アプリケーション設定、インフラ設定) 2. 変更対象のファイルと関連する依存モジュール・型・テストを特定する 3. **書く前に必ず読む**: 対象ファイルと隣接する型定義やテストを Serena で開く ## 2) 最小・レビューしやすい変更 - **1PR = 1目的**。横展開は分割する - 生成コードは **unified diff** を中心に提示 - 不要なフォーマット変更や命名変更は避ける - プロジェクト既存の規約(命名、構成、リンター、フォーマッタ、コミット規約)を尊重する ## 3) セキュリティ・運用面 - 秘密情報(キーやパスワード)は生成せず、ログ出力もしない - 認証/認可/レート制御は既存の仕組みに従う - ログは既存の規約に従い、個人情報はマスクする ## 4) 曖昧な場合の対応 - 不確実な前提は明示し、Serenaで「どのファイル/どの行を読めば確証が取れるか」を提案する - 仕様の不足は **最小仮説** で埋め、代替案やトレードオフも示す --- # 🛠 変更提案時の回答フォーマット 1. **コンテキスト** - Serenaで読んだファイル(最大6件)と主要な発見(6個以内) - 例: src/foo/X.ts:33–88, apps/api/routes/users.py:120–181 2. **差分** - unified diff(インポート・型・テスト含む) 3. **理由** - 根拠・代替案・トレードオフを3〜5点で整理 4. **検証方法** - 検証方法はプロジェクト内の設定ファイルやスクリプトから自動検出し、実際のコマンド例を提示する。 5. **フォローアップ(任意)** - 技術的負債や次のタスク提案 --- # 🔒 絶対ルール - **Serena経由せずに既存コード理解を前提とした提案をしない** - プロジェクト規約は自動検出し遵守 - 不要な巻き込み変更は行わずに修正の提案に留める
使ってみる
- 初回の作業として、「serenaで、このリポジトリをアクティベートしてオンボーディングをしてください。」と入力し、下記の作業を実行させます。
概要
- アクティベート (activate)
• Serena に「今このリポジトリを使います」と教える操作です。
• これをしないと Serena が「どのプロジェクトの記憶を参照すればいいか」分かりません。 - オンボーディング (onboard)
• リポジトリ全体を読み込んで、内部に「記憶(memories)」を作ります。
• これによって Serena はプロジェクトの構成や依存関係を理解でき、以降のコード提案が文脈に沿うようになります。
実際に裏で行われること
- Serena がリポジトリのファイル・設定・依存関係をスキャン
- .serena/memories/ フォルダに、読み込んだ知識を保存
- 以降の質問やコード生成は、この記憶をベースに行われる
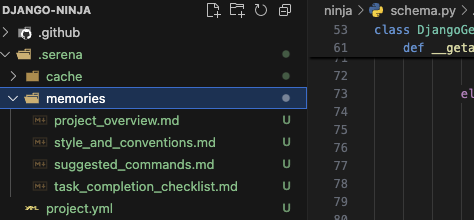
- .serena/配下にファイルが作成されます。
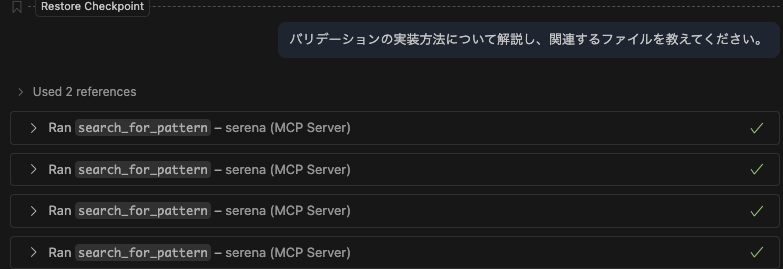
Django NinjaというOSSのリポジトリをクローンして軽く質問してみました。
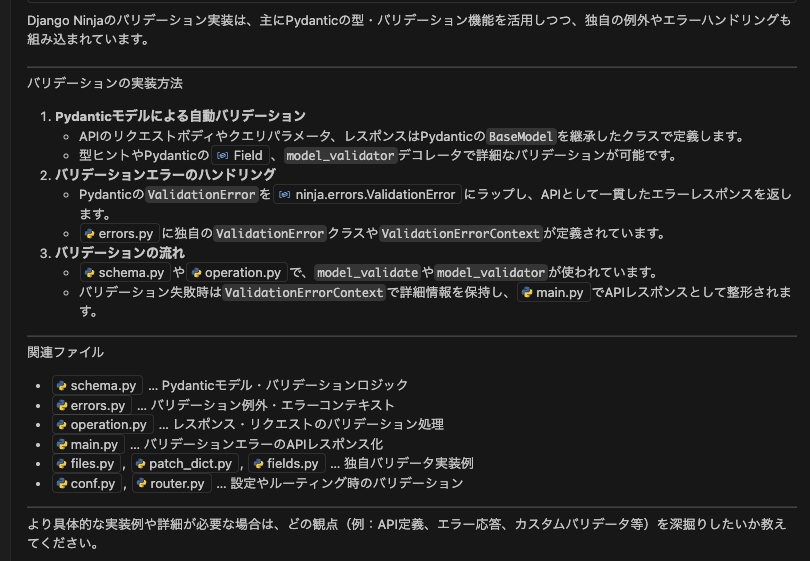
所感
- 使い始めて少ししか経っていないですが、こちら側で読み取るファイルを細かく指定しなくても、関連するコードを探して解答を出してくれるような気がしてます。
- serenaを使う前は、既存コードの設計や流れを汲んで考えてほしいと思うことが多かったのですが、関連するコードを把握する機能が補完されることで、そういった課題が改善されて、生成するコードや解答の質も上がったなぁと感じます。
- 継続使用してみないとなんともですが、今のところは入れていて良かったと思ってます。
Github MCP
設定
- 公式ドキュメントにOAuthによる設定ファイルが書かれているのでそのまま使います。 「⌘ + shift + p」を押して、「MCP: Open User Configration」を選択して設定ファイルに書き込みます。
{
"servers": {
+ "github": {
+ "type": "http",
+ "url": "https://api.githubcopilot.com/mcp/"
+ }
}
}
instructionsファイル例
- PR作成手順に課題を感じていたので、PR作成に焦点を当てた内容にしています。
---
applyTo: '**'
---
# 🧭 PR作成ガイド(GitHub MCP 専用)
> 目的: PR の本文は常に `.github/PULL_REQUEST_TEMPLATE.md` に準拠。テンプレ各セクションを *欠落なく*・*根拠付き* で自動生成し、変更は **適切な粒度でコミット → プッシュ → PR 作成** まで完了させる。
## ✅ 必須ルール
- **テンプレ取得**
- リポジトリから `.github/PULL_REQUEST_TEMPLATE.md` を読み込み、**見出し名・順序・チェックボックスを厳密踏襲**。
- `PULL_REQUEST_TEMPLATE/` ディレクトリがある場合は変更内容に最も適合するテンプレ(例: `feature.md`, `bugfix.md`)を選択。
- 見つからない場合は共通フォールバック(概要・変更点・動機・影響範囲・テスト・スクショ/証跡・関連Issue・破壊的変更・チェックリスト)で生成。
- **根拠の出典(自動要約)**
1) ベースブランチとの差分(changed files / diff)
2) 直近コミットのタイトル/本文
3) 関連 Issue(ブランチ名/コミット/差分から推測してリンク)
4) テスト結果/実行コマンド(スクリプト・CI設定・README)
- **書式厳守**
- テンプレの見出し・順序・チェックボックスは変更しない(未該当は **N/A** 明記)。
- チェックリストは該当を ✅、未確認は ⬜️ のまま。
- 日本語で簡潔・箇条書き優先。コード/コマンドは Markdown コードブロック。
- **安全配慮**
- 秘密情報・トークン・個人情報は本文/差分/ログに出さない。内部 URL は必要に応じてマスク。
- 不要なリフォーマットや無関係ファイルの変更を避ける(既存フォーマッタ/リンタ設定を尊重)。
## 🔧 生成手順(ツール利用の指示)
1) **テンプレ読込**
- `.github/PULL_REQUEST_TEMPLATE.md` → なければ `PULL_REQUEST_TEMPLATE/` → ない場合はフォールバック雛形。
2) **差分とメタ情報の収集**
- 現在ブランチの changed files / diff を取得し、主要変更(追加/削除/リネーム/公開API/大規模ロジック)を抽出。
- 直近コミットをサマリ化。
- ブランチ名・コミット・差分から Issue/チケット番号(`ABC-123`, `#456`)を抽出・リンク。
3) **テンプレ各セクションの自動埋め**
- **概要/目的(Why/What)** は 1–3 行で。
- **変更点** はファイル粒度 → 機能粒度の順で箇条書き。
- **影響範囲**(ユースケース、API/DB/設定、パフォーマンス、後方互換性)。
- **テスト**(追加/更新の有無、再現手順、実行コマンド、ローカル/CI 結果)。
- **スクショ/証跡**(必要なら「要スクショ(未添付)」と明記)。
- **リスク/ロールバック/Feature flag**。
- **関連 Issue**(`Fixes #123` / `Refs #456`)。
- **チェックリスト**(規約/型/テスト/ドキュメント/互換性)。
4) **コミット & プッシュの運用(適切な粒度)**
- 変更は **1 コミット = 1 目的** に分割(例: 型定義追加、バグ修正、テスト追加、ドキュメント更新を別コミット)。
- **コミット前チェック**: Lint/Type/Unit を実行し、失敗したら修正してからステージング。
- **コミットメッセージ規約**: 可能なら Conventional Commits(例: `feat: ...`, `fix: ...`, `refactor: ...`, `test: ...`, `docs: ...`)。
- Body に「背景/方針/影響/代替案」要約、Footer に `Refs/Fixes` を明記。
- 初回 push は **upstream 設定**を行う(例: `git push -u origin <branch>`)。
- コード生成や自動整形は **対象ファイルのみに限定**(ノイズを出さない)。
5) **PR 作成**
- 生成した本文をテンプレ構造どおりに埋めて作成。
- タイトルは「目的が即時に伝わる 50–72 文字」を目安。
- 作成者を Assignee に追加。必要ならレビューア/ラベル/プロジェクトも設定。
6) **最終整形**
- テンプレ構造を変更しないまま本文を整える。1 行 ~120 文字で改行、重複は削除。
## ⚠️ エッジケース
- **巨大差分**: 重要変更トップ 5 を本文で強調、全体は `changed files` 参照にとどめる。
- **モノレポ**: 変更パッケージごとに小見出しを追加して可読性向上。
- **破壊的変更**: 明確に「Breaking Changes」節を設け、移行手順とロールバックを明記。
使ってみる
- PR作成までの流れを自然言語で実行して欲したかったので、試してみました。
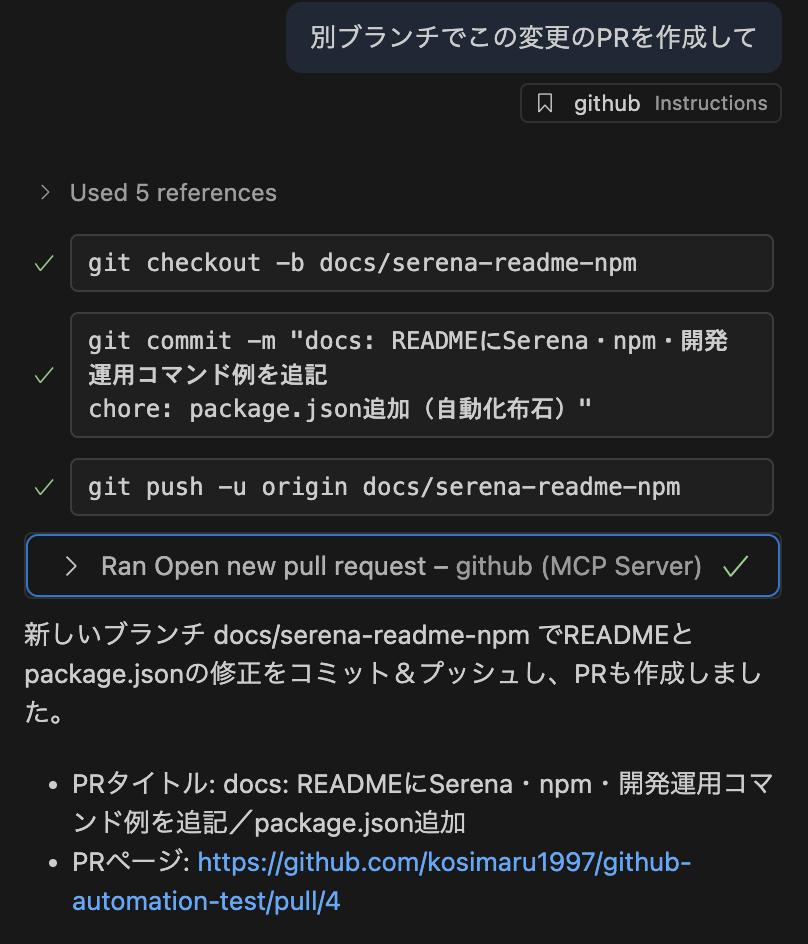
所感
- PRを作ったあとの更新以外は、MCPじゃなくて普通のコマンドラインで実行されてるのですが、
いままで、PRのbody部分が長文すぎるとどれだけ指示を書いてもAgentが実行するシェルがうまく処理されずにPRの更新に失敗していたのが、
MCPサーバーだと最後までやりきってくれて、PRのリンクも乗っけてくれるので結構楽になりました。
おわりに
こういうだたAIを使うみたいな部分のキャッチアップは、さほど学習コストもかからない割に作業効率化の効果が高いこともあるので、
積極的にAIを使用してよりよい時間の使い方をできるようにする必要はあると感じました。(思考停止で使い倒すのは、エンジニアとしてだめだとは思いますが)最近は、AIがどんどん便利になっていて、表現としてのコーディングや実装の価値は下がっていってる感覚があるのですが、 課題を解決するために、「コンピューターになにをさせたいのか、どういう対応が適切か」といった自然言語レベルでの経験や知識には価値があるとも感じています。 AIには力を借りながらも、理解することをサボらずに、まだしばらくはエンジニアと自称できるように頑張っていきたいなと思います。
最後までお読みいただき、ありがとうございました!
弊社ではエンジニアを募集しております。 ぜひカジュアル面談でお話ししましょう! ご興味ありましたら、ご応募ください! Wantedly / Green