
iimonでエンジニアをしています。腰丸です。
iimonの開発では、最近で見積もりや実装工数を記録するようにしていて、
普段は、見積もりスケジュールと照らし合わせて、実装ペースやスケジュール感を把握しています。
感覚的に、「ペース的にうまくいってないかも」とか、「この内容でこの内容のコードなら結構頑張ったかも」みたいな気持ちは持ちながら開発していますが、 成果物の内容を集計、可視化することで、より正確に振り返りや改善点を見つけることができるのではないかと思いました。
弊社では、Githubを使ってコードの管理をしているので、Githubの内容を集計することで、成果物の振り返りができればいいなと思い、 一定期間のGithubの情報を集計してみることにしました。
Githubの情報を集計する
- 何かしらライブラリを使ったり、GithubのRestAPIやGrapeQLを使って情報を使って情報を取得することもできますが、 今回は、Github CLI経由で情報を取得してみます。
集計する情報
実装フェーズでの主な成果物は、PRとレビューの2点になるかと思うので、今回は下記の2点の情報を収集してみます。
- プルリクエスト
- レビューコメント
プルリクエストの集計
- とりあえず、一定期間のPR数と簡単な内容を取得してみます。
gh pr list \ --author "$AUTHOR" \ --repo "$REPO" \ --state all \ --limit 500 \ --json additions,baseRefName,changedFiles,closedAt,createdAt,deletions,headRefName,number,state,title,updatedAt,url \ --search "updated:${START_DATE}..${END_DATE}" \ -q '.[] | select(.state != "CLOSED")' > "$SAVE_FILE"
| オプション | 説明 |
|---|---|
--author "$AUTHOR" |
指定したユーザー($AUTHOR)が作成したプルリクエストに絞り込みます。 |
--repo "$REPO" |
対象のリポジトリ($REPO)を指定します。 |
--state all |
全ての状態(オープン、クローズ、マージ済みなど)のプルリクエストを対象にします。 |
--limit 500 |
取得するプルリクエストの最大件数を 500 件に制限します。 |
--json additions,baseRefName,changedFiles,closedAt,createdAt,deletions,headRefName,number,state,title,updatedAt,url |
出力する JSON のフィールドを指定しています。各プルリクエストの詳細情報を取得可能です。 |
--search "updated:${START_DATE}..${END_DATE}" |
プルリクエストの更新日時が指定した範囲($START_DATE から $END_DATE)にあるものに絞り込みます。 |
-q '.[] | select(.state != "CLOSED")' |
jq のクエリを用いて、状態が CLOSED 以外のプルリクエストのみを抽出します。 |
> "$SAVE_FILE" |
コマンドの出力結果を指定のファイル($SAVE_FILE)に保存します。 |
- 最終的なシェル
#!/bin/bash # デフォルト値を設定 AUTHOR="" REPO="" # 引数をパース while [[ $# -gt 0 ]]; do case "$1" in --author) AUTHOR="$2" shift 2 ;; --repo) REPO="$2" shift 2 ;; *) echo "Unknown option: $1" exit 1 ;; esac done # AUTHORとREPOが指定されていない場合のエラー処理 if [[ -z "$AUTHOR" || -z "$REPO" ]]; then echo "Usage: $0 --author <author> --repo <repo>" echo "Example: $0 --author kosimaru1997 --repo sample-repo" exit 1 fi # 直近3ヶ月を指定 END_DATE=$(date '+%Y-%m-%d') START_DATE=$(date -v-3m '+%Y-%m-%d') # 保存先ディレクトリを動的に作成 SAVE_DIR="pr_list/$REPO/$AUTHOR" mkdir -p "$SAVE_DIR" # ディレクトリが存在しない場合は作成 SAVE_FILE="$SAVE_DIR/pr_list_${START_DATE}_to_${END_DATE}.json" # gh コマンドの実行 gh pr list \ --author "$AUTHOR" \ --repo "$REPO" \ --state all \ --limit 500 \ --json additions,baseRefName,changedFiles,closedAt,createdAt,deletions,headRefName,number,state,title,updatedAt,url \ --search "updated:${START_DATE}..${END_DATE}" \ -q '.[] | select(.state != "CLOSED")' > "$SAVE_FILE" echo "PRリストが保存されました: $SAVE_FILE" echo "期間: ${START_DATE}~${END_DATE}"
- 実行例
./pr_list.sh --author kosimaru1997 --repo fast-api-sterter
- 結果例
{"additions":266,"baseRefName":"main","changedFiles":8,"closedAt":"2025-01-18T14:12:38Z","createdAt":"2025-01-18T13:56:57Z","deletions":7,"headRefName":"feaure/add_pydantic_settings","number":5,"state":"MERGED","title":"環境変数の読み込み設定","updatedAt":"2025-01-18T14:12:42Z","url":"https://github.com/kosimaru1997/fast-api-sterter/pull/5"} {"additions":637,"baseRefName":"main","changedFiles":10,"closedAt":"2025-01-18T13:49:11Z","createdAt":"2025-01-14T23:44:24Z","deletions":19,"headRefName":"feaure/add_sql_model","number":4,"state":"MERGED","title":"feat: alembicの設定を追加","updatedAt":"2025-01-18T13:54:43Z","url":"https://github.com/kosimaru1997/fast-api-sterter/pull/4"}
コメントの集計
- コメントの集計は、下記のGithub RestAPIを使って取得します。
(コードにハイライトを当てるレビューコメントと、ハイライトを当てていない場合のissueコメントは、別で扱われているらしいので、上記2点のAPIを使ってそれぞれの内容を取得します)
最終的なシェルの内容
#!/bin/bash # ==== 引数チェック ==== if [ "$#" -lt 1 ]; then echo "Usage: $0 <repository>" echo "例: $0 kosimaru1997/fast-api-sterter" exit 1 fi # ==== 設定 ==== REPO="$1" BASE_DIR="comment_list/$REPO" mkdir -p "$BASE_DIR" SINCE_DATE=$(date -v-3m '+%Y-%m-%d') # 過去三ヶ月分 PR_CHECK_DATE=$(date -u -v-150d '+%Y-%m-%dT%H:00:00Z') # 過去約半年分 PR_AUTHORS_FILE="$BASE_DIR/pr_authors.json" FILTERED_PR_COMMENTS_FILE="$BASE_DIR/filtered_pr_comments.json" FILTERED_ISSUE_COMMENTS_FILE="$BASE_DIR/filtered_issue_comments.json" FILTERED_COMMENTS_FILE="$BASE_DIR/filtered_comments.json" TMP_COMMENTS_FILE="$BASE_DIR/tmp_comments.jsonl" TMP_ISSUE_COMMENTS_FILE="$BASE_DIR/tmp_issue_comments.jsonl" AUTHOR_FILES_DIR="$BASE_DIR/comments_by_author" # ==== 関数: コメント取得 ==== fetch_comments() { local url="$1" local output_file="$2" echo "📥 Fetching comments from $url..." response=$(gh api "$url" --include) json_body=$(echo "$response" | sed -n '/^\[/,$p') if ! echo "$json_body" | jq empty 2>/dev/null; then echo "⚠️ Invalid JSON response." return fi echo "$json_body" | jq -c '.[]' >> "$output_file" next_url=$(echo "$response" | sed -n 's/.*<\([^>]*\)>; rel="next".*/\1/p') if [[ -n "$next_url" ]]; then fetch_comments "$next_url" "$output_file" fi } # ==== PR作成者を取得 ==== echo "📥 Fetching PR authors for repository: $REPO" gh pr list --repo "$REPO" --search "updated:>$PR_CHECK_DATE" --state all --limit 1000 --json author,number \ | jq '[.[] | {id: .number, author: .author.login}]' > "$PR_AUTHORS_FILE" echo "✅ PR authors saved to $PR_AUTHORS_FILE" # ==== PRコメントを取得 ==== echo "📥 Fetching PR comments..." > "$TMP_COMMENTS_FILE" fetch_comments "repos/$REPO/pulls/comments?since=$SINCE_DATE&per_page=100" "$TMP_COMMENTS_FILE" # ==== Issueコメントを取得 ==== echo "📥 Fetching Issue comments..." > "$TMP_ISSUE_COMMENTS_FILE" fetch_comments "repos/$REPO/issues/comments?since=$SINCE_DATE&per_page=100" "$TMP_ISSUE_COMMENTS_FILE" # ==== PRコメントをフィルタリング ==== echo "📦 Filtering PR comments..." jq --slurpfile pr_authors "$PR_AUTHORS_FILE" --slurp ' map( . as $original | ($original.pull_request_url | capture(".*/pulls/(?<pr_number>[0-9]+)$").pr_number | tonumber) as $pr | ($pr_authors[0][] | select(.id == $pr) | .author // null) as $pr_author | { pr_number: $pr, id: $original.id, diff_hunk: $original.diff_hunk, body: $original.body, html_url: $original.html_url, comments_author: $original.user.login, pr_author: $pr_author, path: $original.path, line: $original.line, created_at: $original.created_at, updated_at: $original.updated_at } ) | map(select(.pr_author != .comments_author)) ' "$TMP_COMMENTS_FILE" > "$FILTERED_PR_COMMENTS_FILE" echo "✅ Filtered PR comments saved to $FILTERED_PR_COMMENTS_FILE" # ==== Issueコメントをフィルタリング ==== echo "📦 Filtering Issue comments..." jq --slurpfile pr_authors "$PR_AUTHORS_FILE" --slurp ' map( . as $original | ($original.issue_url | capture(".*/issues/(?<pr_number>[0-9]+)$").pr_number | tonumber) as $pr | ($pr_authors[0][] | select(.id == $pr) | .author // null) as $pr_author | { pr_number: $pr, id: $original.id, body: $original.body, html_url: $original.html_url, comments_author: $original.user.login, pr_author: $pr_author, created_at: $original.created_at, updated_at: $original.updated_at } ) | map(select(.pr_author != .comments_author and (.body | contains("![LGTM]") | not))) ' "$TMP_ISSUE_COMMENTS_FILE" > "$FILTERED_ISSUE_COMMENTS_FILE" echo "✅ Filtered Issue comments saved to $FILTERED_ISSUE_COMMENTS_FILE" # ==== PRコメントとIssueコメントをマージ ==== echo "📦 Merging filtered comments..." jq -s 'add' "$FILTERED_PR_COMMENTS_FILE" "$FILTERED_ISSUE_COMMENTS_FILE" > "$FILTERED_COMMENTS_FILE" echo "✅ All filtered comments saved to $FILTERED_COMMENTS_FILE" # ==== コメントをauthorごとに分割保存 ==== echo "📂 Splitting comments by author..." rm -rf "$AUTHOR_FILES_DIR" mkdir -p "$AUTHOR_FILES_DIR" jq -c '.[] | {pr_author, comments_author, body, pr_number, diff_hunk, path, line, html_url, created_at}' "$FILTERED_COMMENTS_FILE" \ | jq -s ' group_by(.comments_author) | map({ author: .[0].comments_author, comments: (sort_by(.pr_number, .created_at)) })' \ | jq -c '.[]' | while read -r author_data; do author=$(echo "$author_data" | jq -r '.author') comments=$(echo "$author_data" | jq '.comments') file_path="$AUTHOR_FILES_DIR/${author}.json" echo "$comments" > "$file_path" echo "✅ Saved comments for $author to $file_path" done echo "🎉 All comments have been saved by author in $AUTHOR_FILES_DIR"
コメント取得の概要
- 一定期間のPRコメント、issueコメントを取得
- PRコメント,issueコメントのAuthorとコメントのAuthorが一致している場合を除外
- ![LGTM] が含まれるコメントを除外
- comment_list/{リポジトリ名}の配下に、上記のコメントを除外した内容を保存
- Authorごとのコメント内容をcomment_list/{リポジトリ名}/comments_by_author配下に保存
シェルスクリプトの解説
fetch_comments 関数
Github API を利用して、PR コメントや Issue コメントを再帰的に取得します。
fetch_comments() { local url="$1" local output_file="$2" echo "📥 Fetching comments from $url..." response=$(gh api "$url" --include) json_body=$(echo "$response" | sed -n '/^\[/,$p') if ! echo "$json_body" | jq empty 2>/dev/null; then echo "⚠️ Invalid JSON response." return fi echo "$json_body" | jq -c '.[]' >> "$output_file" next_url=$(echo "$response" | sed -n 's/.*<\([^>]*\)>; rel="next".*/\1/p') if [[ -n "$next_url" ]]; then fetch_comments "$next_url" "$output_file" fi }
gh api "$url" --include により、指定した Github API エンドポイントからデータを取得します。 --include オプションでレスポンスヘッダーも含め、ページング情報(次ページのURLなど)を取得できるようにしています。
JSON パースとページング対応:
sed と jq を組み合わせ、レスポンスから JSON 部分を抽出し、各コメントを JSON Lines 形式で出力ファイルに保存します。 ヘッダーから rel="next" 部分を抽出し、再帰的に次ページのデータも取得します。
echo "📥 Fetching PR authors for repository: $REPO" gh pr list --repo "$REPO" --search "updated:>$PR_CHECK_DATE" --state all --limit 1000 --json author,number \ | jq '[.[] | {id: .number, author: .author.login}]' > "$PR_AUTHORS_FILE"
--repo "$REPO" で対象リポジトリを指定。 --search "updated:>$PR_CHECK_DATE" で更新日時による絞り込みを行います。 --state all で全状態の PR を対象にし、--json author,number で必要なフィールドだけを抽出します。 jq による整形:
取得した JSON データから、PR 番号と作成者のログイン名のみを抽出し、後のフィルタリング処理に利用できる形式に整形しています。 1. コメントの取得
Github API のエンドポイントを利用して、PR コメントを取得します。
echo "📥 Fetching PR comments..." > "$TMP_COMMENTS_FILE" fetch_comments "repos/$REPO/pulls/comments?since=$SINCE_DATE&per_page=100" "$TMP_COMMENTS_FILE"
エンドポイントとパラメータ: repos/$REPO/pulls/comments: PR コメントを取得する API エンドポイントです。 since=$SINCE_DATE: 過去3ヶ月分に絞り込んでいます。 per_page=100: 1ページあたりの取得件数を指定しています。 Issue コメントの取得 同様に Issue コメントも取得します。
echo "📥 Fetching Issue comments..." > "$TMP_ISSUE_COMMENTS_FILE" fetch_comments "repos/$REPO/issues/comments?since=$SINCE_DATE&per_page=100" "$TMP_ISSUE_COMMENTS_FILE"
エンドポイント: repos/$REPO/issues/comments: Issue コメントを取得する API エンドポイントです。
- 取得したコメントのフィルタリング PR コメントのフィルタリング PR コメントから、PR 作成者自身のコメント(=自動生成やレビュー依頼に起因しない、実際のレビュー以外のコメント)を除外します。
echo "📦 Filtering PR comments..." jq --slurpfile pr_authors "$PR_AUTHORS_FILE" --slurp ' map( . as $original | ($original.pull_request_url | capture(".*/pulls/(?<pr_number>[0-9]+)$").pr_number | tonumber) as $pr | ($pr_authors[0][] | select(.id == $pr) | .author // null) as $pr_author | { pr_number: $pr, id: $original.id, diff_hunk: $original.diff_hunk, body: $original.body, html_url: $original.html_url, comments_author: $original.user.login, pr_author: $pr_author, path: $original.path, line: $original.line, created_at: $original.created_at, updated_at: $original.updated_at } ) | map(select(.pr_author != .comments_author)) ' "$TMP_COMMENTS_FILE" > "$FILTERED_PR_COMMENTS_FILE"
ポイント: pull_request_url から PR 番号を抽出し、対応する PR 作成者を照合します。 作成者とコメント投稿者が一致しないコメントのみをフィルタリングして残します。 Issue コメントのフィルタリング Issue コメントも同様に、不要なコメント(例えば、PR作成者のコメントや特定のマークアップが含まれるもの)を除外します。
echo "📦 Filtering Issue comments..." jq --slurpfile pr_authors "$PR_AUTHORS_FILE" --slurp ' map( . as $original | ($original.issue_url | capture(".*/issues/(?<pr_number>[0-9]+)$").pr_number | tonumber) as $pr | ($pr_authors[0][] | select(.id == $pr) | .author // null) as $pr_author | { pr_number: $pr, id: $original.id, body: $original.body, html_url: $original.html_url, comments_author: $original.user.login, pr_author: $pr_author, created_at: $original.created_at, updated_at: $original.updated_at } ) | map(select(.pr_author != .comments_author and (.body | contains("![LGTM]") | not))) ' "$TMP_ISSUE_COMMENTS_FILE" > "$FILTERED_ISSUE_COMMENTS_FILE"
ポイント: issue_url から PR 番号を抽出し、PR 作成者とコメント投稿者が異なるコメントだけを残します。 特定のパターン(例: ![LGTM] が含まれるもの)も除外しています。
- コメントの統合と author ごとの分割 コメントの統合 フィルタリングされた PR コメントと Issue コメントを 1 つのファイルにまとめます。
jq -s 'add' "$FILTERED_PR_COMMENTS_FILE" "$FILTERED_ISSUE_COMMENTS_FILE" > "$FILTERED_COMMENTS_FILE"
ポイント: jq -s 'add' を使用して、複数の JSON ファイルを配列として結合します。 コメントの author ごとの分割 取得した全コメントを、コメント投稿者ごとにグループ化し、個別のファイルに保存します。
echo "📂 Splitting comments by author..." rm -rf "$AUTHOR_FILES_DIR" mkdir -p "$AUTHOR_FILES_DIR" jq -c '.[] | {pr_author, comments_author, body, pr_number, diff_hunk, path, line, html_url, created_at}' "$FILTERED_COMMENTS_FILE" \ | jq -s ' group_by(.comments_author) | map({ author: .[0].comments_author, comments: (sort_by(.pr_number, .created_at)) })' \ | jq -c '.[]' | while read -r author_data; do author=$(echo "$author_data" | jq -r '.author') comments=$(echo "$author_data" | jq '.comments') file_path="$AUTHOR_FILES_DIR/${author}.json" done
ポイント: jq の group_by 関数で、comments_author ごとにグループ化します。 各グループは、PR 番号と作成日時でソートされ、個別の JSON ファイル(${author}.json)として保存されます。
- 実行例
./comment_list.sh kosimaru1997/fast-api-sterter
- 結果
作成されるファイル
.comment_list
└── kosimaru1997
└── fast-api-sterter
├── comments_by_author
│ └── kosimaru19970128.json // ユーザーごとのコメント
├── filtered_comments.json. // 不要なコメントを除外した全コメント一覧
├── filtered_issue_comments.json
├── filtered_pr_comments.json
├── pr_authors.json. // PR番号とAuthorの一覧
├── tmp_comments.jsonl
└── tmp_issue_comments.jsonl
- ファイルの内容例
[ { "pr_author": "kosimaru1997", "comments_author": "kosimaru19970128", "body": "別アカウントのコメント", "pr_number": 5, "diff_hunk": "@@ -0,0 +1,10 @@\n+# MySQL関連\n+# MYSQL_ROOT_PASSWORD=root\n+\n+MYSQL_HOST=mysql\n+MYSQL_PORT=3306", "path": "containers/api/api.env", "line": 5, "html_url": "https://github.com/kosimaru1997/fast-api-sterter/pull/5#discussion_r1958421331", "created_at": "2025-02-17T15:28:02Z" }, { "pr_author": "kosimaru1997", "comments_author": "kosimaru19970128", "body": "別アカウントのissueコメント", "pr_number": 5, "diff_hunk": null, "path": null, "line": null, "html_url": "https://github.com/kosimaru1997/fast-api-sterter/pull/5#issuecomment-2663443587", "created_at": "2025-02-17T15:28:24Z" } ...
ここまでで、今回欲しい情報の集計はできました!
おまけ(集計したデータを使ってみる)
集計したデータの使用例としてグラフ化をしてみます。具体的な、実装の説明内容は割愛しますが、「Electron」と「plotly」というライブラリを用いて素朴に実装してみました。
- グラフ化部分の実装コード(一部抜粋)
plotlyの実装部分
document.getElementById("pr-list-button").addEventListener("click", async () => { console.log("🚀 PRリストを取得します"); // セレクタから選択された値を取得 const author = document.getElementById("author-list").value; const repository = document.getElementById("repo-list").value; // 入力チェック if (!author || !repository) { document.getElementById("pr-button-output").textContent = "❌ アカウントまたはリポジトリが選択されていません"; return; } try { // シェルスクリプトを実行し、結果を取得 const res = await window.shell.prList(author, repository); document.getElementById("pr-button-output").textContent = res; } catch (error) { console.error("❌ エラー:", error); document.getElementById("pr-button-output").textContent = "エラーが発生しました。"; } }); // 日本の祝日リスト(例:建国記念の日) const holidays = ["2025-02-11"]; // YYYY-MM-DD形式 // 指定された期間内のすべての土日を計算する関数 function calculateWeekends(startDate, endDate) { const weekends = []; const currentDate = new Date(startDate); while (currentDate <= new Date(endDate)) { const day = currentDate.getDay(); if (day === 0 || day === 6) { // 日曜日(0)または土曜日(6)の場合 weekends.push(currentDate.toISOString().slice(0, 10)); } currentDate.setDate(currentDate.getDate() + 1); // 次の日へ } return weekends; } // チャートを描画する関数 // fileContent を引数に追加して、FileReader で読み取ったテキストを利用する function drawChart(chartId, startStr, endStr, fileContent) { // JSONファイルの内容は、各行が1つのJSONオブジェクトになっている前提 const prData = fileContent.trim().split("\n").map(line => JSON.parse(line)); // 各PRの "createdAt" と "closedAt" を "start" と "finish" として YYYY-MM-DD 形式に変換 prData.forEach(pr => { pr.start = pr.createdAt ? pr.createdAt.slice(0, 10) : null; pr.finish = pr.closedAt ? pr.closedAt.slice(0, 10) : pr.updatedAt.slice(0, 10); const finishDate = new Date(pr.finish); finishDate.setDate(finishDate.getDate() + 1); pr.finish = finishDate.toISOString().slice(0, 10); }); // 有効な日付と指定の期間のデータのみをフィルタリング const validPRData = prData.filter( pr => pr.start && pr.finish && !isNaN(new Date(pr.start)) && !isNaN(new Date(pr.finish)) && pr.start <= endStr && pr.finish >= startStr ); if (validPRData.length === 0) { throw new Error("有効な日付データがありません"); } // トレースデータを作成 const traces = validPRData.map(pr => ({ x: [pr.start, pr.finish], y: [pr.title, pr.title], mode: 'lines', line: { width: 20 }, type: 'scatter', hoverinfo: 'text', hoverlabel: { align: 'left' }, // テキストを左揃えにする text: ` <b>タイトル:</b> ${pr.title}<br> <b>PR番号:</b> ${pr.number}<br> <b>期間:</b> ${pr.start} ~ ${pr.finish}<br> <b>変更行数:</b> +${pr.additions} / -${pr.deletions}<br> <b>変更ファイル数:</b> ${pr.changedFiles}<br> `, showlegend: false })); // 期間内の土日を計算して祝日リストと結合 const weekends = calculateWeekends(startStr, endStr); const grayDates = [...holidays, ...weekends]; // 祝日と土日をグレーアウトするための shapes を作成 const grayShapes = grayDates.map(date => ({ type: 'rect', xref: 'x', yref: 'paper', x0: date, x1: new Date(new Date(date).getTime() + 86400000).toISOString().slice(0, 10), y0: 0, y1: 1, fillcolor: 'gray', opacity: 0.2, line: { width: 0 } })); // チャートレイアウト const layout = { title: `PR一覧ガントチャート`, xaxis: { type: "date", range: [startStr, endStr], tickformat: "%Y-%m-%d", dtick: 86400000, automargin: true, }, yaxis: { automargin: true, autorange: "reversed", tickfont: { size: 10 } }, margin: { l: 250, r: 50, t: 50, b: 50 }, shapes: grayShapes, // 土日・祝日をグレーアウト width: 1200, height: 800 }; Plotly.newPlot(chartId, traces, layout); } // 「チャートを描画」ボタンのクリックイベントに処理を割り当て document.getElementById('draw_chart').addEventListener('click', () => { const startStr = document.getElementById('start_date').value; const endStr = document.getElementById('end_date').value; if (!startStr || !endStr) { alert("開始日と終了日を選択してください。"); return; } // ファイル入力要素を取得 const prFile = document.getElementById('pr-file-input'); if (!prFile.files || prFile.files.length === 0) { alert("JSONファイルを選択してください。"); return; } const file = prFile.files[0]; file.arrayBuffer() .then(buffer => { const decoder = new TextDecoder('utf-8'); const fileContent = decoder.decode(buffer); try { drawChart('chart', startStr, endStr, fileContent); } catch (error) { console.error("チャート描画エラー:", error); alert("チャートの描画中にエラーが発生しました。"); } }) .catch(error => { console.error("ファイル読み込みエラー", error); alert("JSONファイルの読み込みに失敗しました。"); }); }); document.getElementById("comment-list-button").addEventListener("click", async () => { console.log("🚀 Commentリストを取得します"); // セレクタから選択された値を取得 const repository = document.getElementById("comment-repo-list").value; // 入力チェック if (!repository) { document.getElementById("comment-button-output").textContent = "❌ アカウントまたはリポジトリが選択されていません"; return; } try { // シェルスクリプトを実行し、結果を取得 const res = await window.shell.commentList(repository); document.getElementById("comment-button-output").textContent = ' ✅️ Commentリストを取得しました'; } catch (error) { console.error("❌ エラー:", error); document.getElementById("comment-button-output").textContent = "エラーが発生しました。"; } }); function authorCommentGraph(graphId, startStr, endStr, fileContent) { const commentsData = JSON.parse(fileContent); // 開始日・終了日でコメントをフィルタ let filteredCommentsData = commentsData; if (startStr) { filteredCommentsData = filteredCommentsData.filter(comment => { const date = new Date(comment.created_at); return date >= new Date(startStr); }); } if (endStr) { filteredCommentsData = filteredCommentsData.filter(comment => { const date = new Date(comment.created_at); return date <= new Date(endStr); }); } // 日付ごとにカウント const dateCounts = {}; filteredCommentsData.forEach(item => { const date = item.created_at ? item.created_at.slice(0, 10) : null; // "YYYY-MM-DD" if (date) { dateCounts[date] = (dateCounts[date] || 0) + 1; } }); // 土日・祝日リストを結合 const weekends = calculateWeekends(startStr, endStr); // ユーザー定義関数: 期間内の土日を返す const grayDates = [...holidays, ...weekends]; // holidays: 祝日リスト // 日付のソート const sortedDates = Object.keys(dateCounts).sort(); const counts = sortedDates.map(date => dateCounts[date]); // グレーアウト用の shapes を生成 // 1日単位で矩形を描画して塗りつぶす const grayShapes = grayDates.map(dateStr => ({ type: 'rect', xref: 'x', yref: 'paper', x0: dateStr, x1: new Date(new Date(dateStr).getTime() + 86400000).toISOString().slice(0, 10), y0: 0, y1: 1, fillcolor: 'gray', opacity: 0.2, line: { width: 0 } })); // グラフ用トレース const trace = { x: sortedDates, y: counts, type: 'bar', marker: { color: 'rgb(100, 150, 250)' } }; // Layout 設定 const layout = { title: '日付ごとのPR数', xaxis: { title: '日付', type: 'date', range: [startStr, endStr], tickformat: '%Y-%m-%d', // 1日刻みでグリッドラインを表示するための設定 tickmode: 'linear', dtick: 86400000, // 1日分(24*60*60*1000)のミリ秒 showgrid: true, // グリッドラインを表示 automargin: true }, yaxis: { title: 'Comment数' }, margin: { t: 50, l: 60, r: 30, b: 50 }, shapes: grayShapes, // 土日・祝日をグレーアウト width: 1200, height: 700 }; Plotly.newPlot(graphId, [trace], layout); } document.getElementById('author-comment-graph-input').addEventListener('click', () => { const startStr = document.getElementById('author_comment_start_date').value; const endStr = document.getElementById('author_comment_end_date').value; if (!startStr || !endStr) { alert("開始日と終了日を選択してください。"); return; } // ファイル入力要素を取得 const commentFile = document.getElementById('author-comment-file-input'); const file = commentFile.files[0]; file.arrayBuffer() .then(buffer => { const decoder = new TextDecoder('utf-8'); const fileContent = decoder.decode(buffer); try { authorCommentGraph('author-comment-graph', startStr, endStr, fileContent); } catch (error) { console.error("Commentグラフ描画エラー:", error); alert("Commentグラフ描画中にエラーが発生しました。"); } }) .catch(error => { console.error("ファイル読み込みエラー", error); alert("JSONファイルの読み込みに失敗しました。"); }); }); function commentGraphByAuthor(graphId, startStr, endStr, fileContent) { console.log("🚀 Commentリストを取得します"); const commentsData = JSON.parse(fileContent); let filteredCommentsData = commentsData; if (startStr) { filteredCommentsData = filteredCommentsData.filter(comment => { const date = new Date(comment.created_at); return date >= new Date(startStr); }); } if (endStr) { filteredCommentsData = filteredCommentsData.filter(comment => { const date = new Date(comment.created_at); return date <= new Date(endStr); }); } // Authorごとのコメント数を集計 const authorCounts = {}; filteredCommentsData.forEach((item) => { authorCounts[item.comments_author] = (authorCounts[item.comments_author] || 0) + 1; }); console.log("📊 Authorごとのコメント数:", authorCounts); // authorCounts オブジェクトから、作者名(キー)とコメント数(値)の配列を作成 const authors = Object.keys(authorCounts); const counts = authors.map(author => authorCounts[author]); // Plotly のトレース設定(バーチャート) const trace = { x: authors, y: counts, type: 'bar', marker: { color: 'rgb(129, 189, 230)' } }; // レイアウトの設定 const layout = { title: 'Authorごとのコメント数', xaxis: { title: 'Author' }, yaxis: { title: 'コメント数' }, width: 1200, height: 800 }; // グラフを描画 Plotly.newPlot(graphId, [trace], layout); } document.getElementById('comment-graph-by-author').addEventListener('click', () => { const startStr = document.getElementById('comment_start_date').value; const endStr = document.getElementById('comment_end_date').value; // ファイル入力要素を取得 const commentFile = document.getElementById('comment-file-input'); const file = commentFile.files[0]; file.arrayBuffer() .then(buffer => { const decoder = new TextDecoder('utf-8'); const fileContent = decoder.decode(buffer); try { commentGraphByAuthor('comment-graph', startStr, endStr, fileContent); } catch (error) { console.error("Commentグラフ描画エラー:", error); alert("Commentグラフ描画中にエラーが発生しました。"); } }) .catch(error => { console.error("ファイル読み込みエラー", error); alert("JSONファイルの読み込みに失敗しました。"); }); });
実際の画面
- 全体
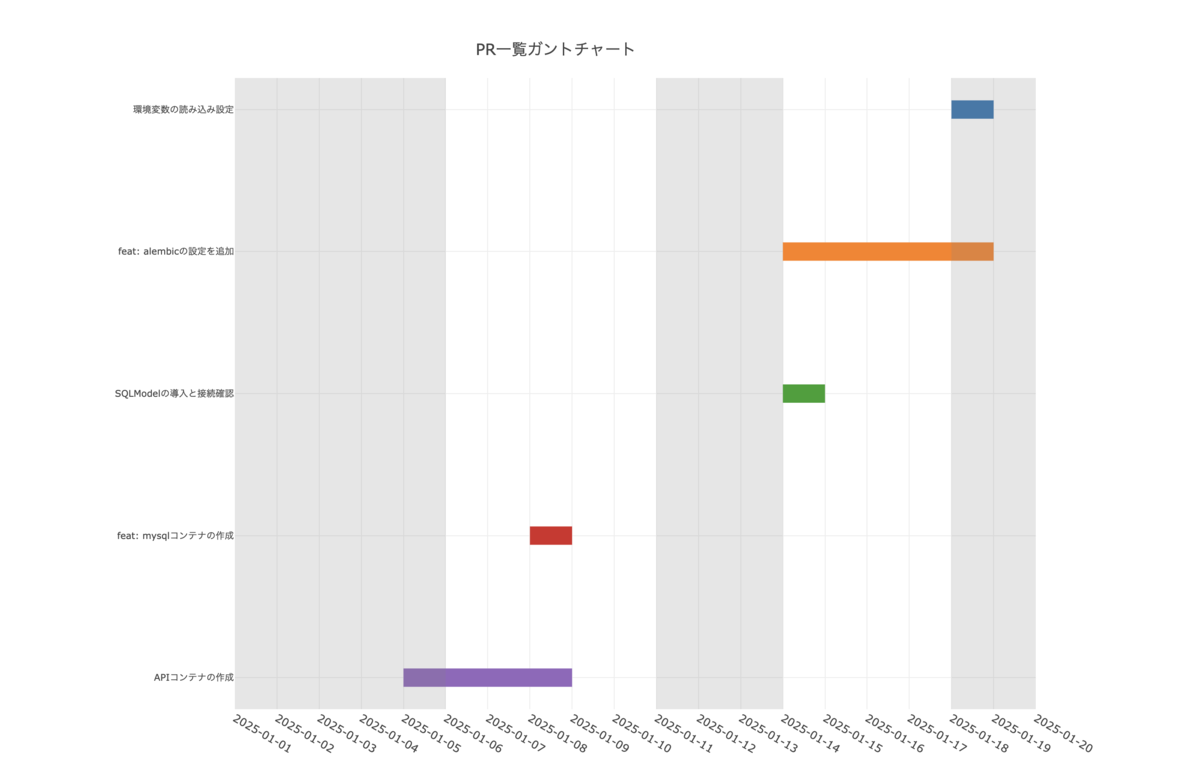
PRガントチャート
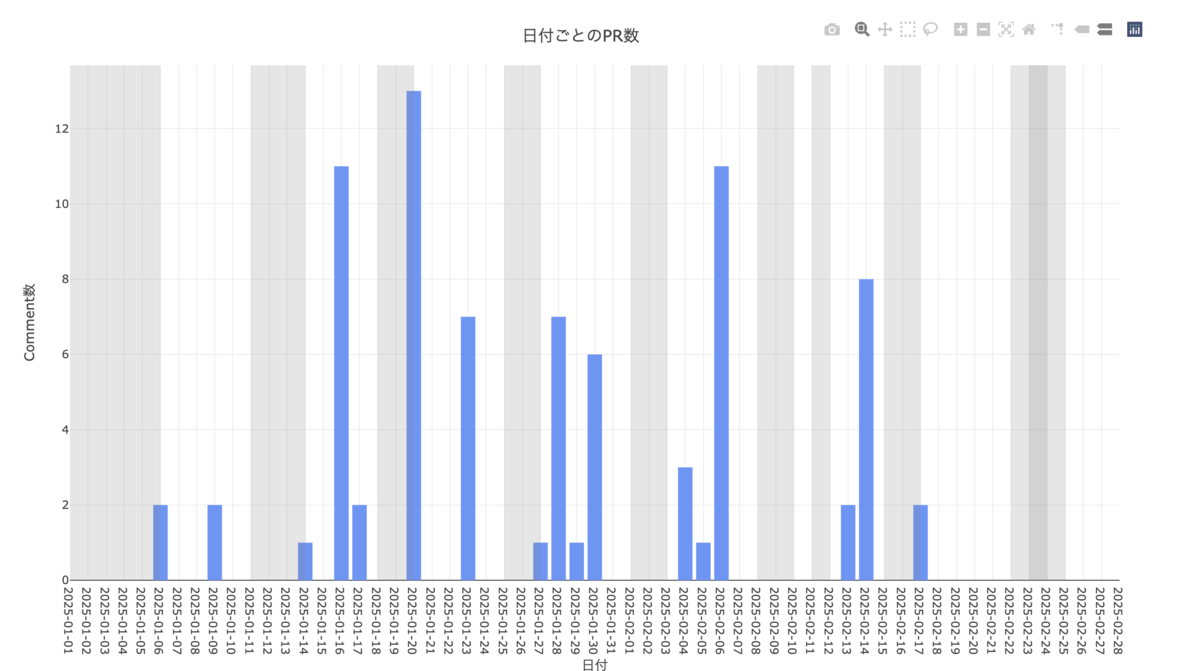
日付ごとのコメント数
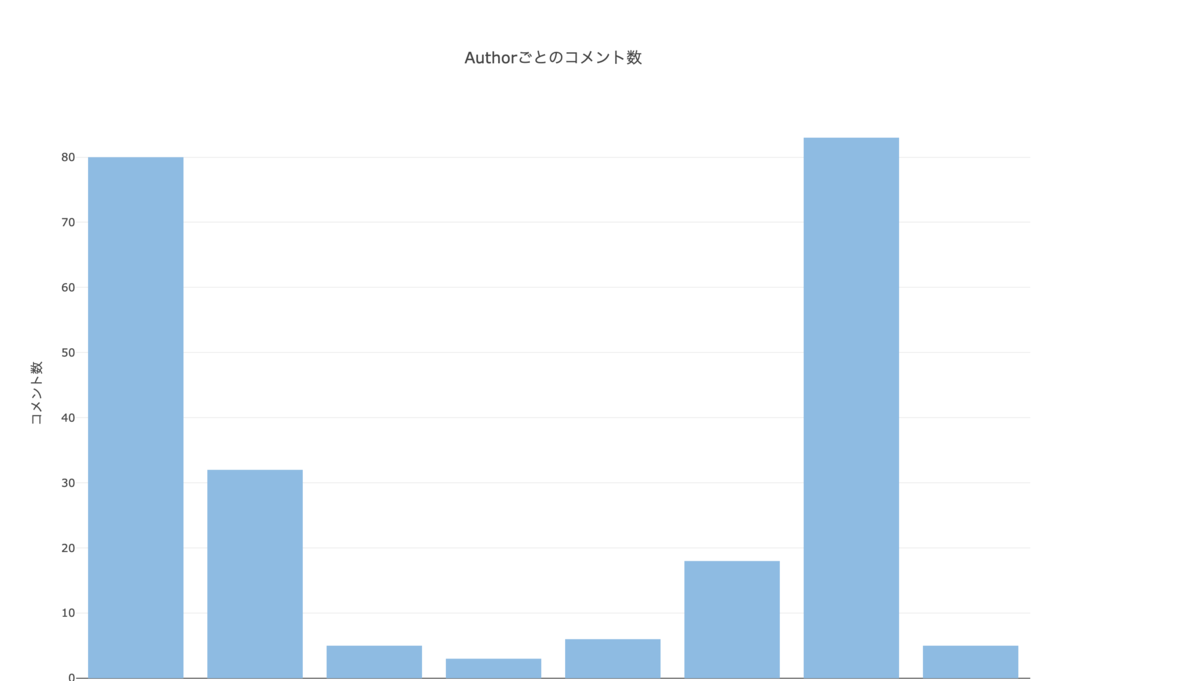
Authorごとのコメント数
大まかな概要ベースでの可視化もできたので、感覚的だった実装ペースと成果物の内容の自己評価が、多少は具体的にできるのかなと思います。
まとめ
ざっくりとした内容にはなりましたが、Githubのデータの集計をしてみました。 今回のデータの使い方は、概要部分の可視化でしたが、 PRのdiffやPRコメントの内容をOpenAIに読ませて、客観的な評価をさせてみたり、 もっと具体的な実装コードやPRコメントの内容を みやすくすることもできるのかなと思います。
GithubのRestAPIやGraphQLを使うと、思ったより情報の整理ができて楽しいので、今後も色々と触ってみつつ、エンジニアとしての活動の振り返りができたらなと思いました。
ここまでお読みいただき、ありがとうございます。
弊社ではエンジニアを募集しております。
この記事を読んで少しでも興味を持ってくださった方は、ぜひカジュアル面談でお話ししましょう!
下記リンクよりご応募お待ちしております!
iimon採用サイト / Wantedly / Green