こんにちは、CTOの森です。 本記事はiimonアドベントカレンダー16日目の記事となります。 普段機械学習を使うことは無いのですが、勉強も兼ねてCloudFrontのログを機械学習させてみたらどうなるのか試してみました。
今回ログデータをIsolation Forestという手法を用いて分析してみました。Isolation Forestとは異常検知に最適な教師なしの機械学習方法とのことです。
検証した環境
今回Google Colaboratoryを使用して試しています。
CloudFrontのログをいくつかダウンロードして、Google Drive上にアップロードしてそれをGoogle Colaboratoryにて参照して検証しています。
マウントはファイルからドライブをマウントを押すだけで出来ます。

ログデータの形式
今回使用したCloudFrontのログデータは下記の様になっていました(ドメインやIPアドレスやAPIのパスなどについては伏せています) こういったログを10,273行使用しています。
#Version: 1.0 #Fields: date time x-edge-location sc-bytes c-ip cs-method cs(Host) cs-uri-stem sc-status cs(Referer) cs(User-Agent) cs-uri-query cs(Cookie) x-edge-result-type x-edge-request-id x-host-header cs-protocol cs-bytes time-taken x-forwarded-for ssl-protocol ssl-cipher x-edge-response-result-type cs-protocol-version fle-status fle-encrypted-fields c-port time-to-first-byte x-edge-detailed-result-type sc-content-type sc-content-len sc-range-start sc-range-end 2023-12-01 00:47:57 NRT12-C3 519 xxx.xxx.xxx.xxx OPTIONS ddddd.cloudfront.net /api/aaa/ 200 https://example.com/ Mozilla/5.0%20(Windows%20NT%2010.0;%20Win64;%20x64)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/119.0.0.0%20Safari/537.36 - - Miss XXXXXXXXXXXXXXXXXXXX== example.com https 358 0.009 - TLSv1.3 TLS_AES_128_GCM_SHA256 Miss HTTP/2.0 - - 52042 0.009 Miss text/html;%20charset=utf-8 0 - -
使用したログデータのフィールド
今回分析で使用する値には下記フィールドを選定してベクトルデータに加工して分析しました。この時の想定ではAPIごとに遅いリクエストが抽出出来たら良いなーという感じでした。
| フィールド名 | 内容 |
|---|---|
| cs-method | ビューワーから受信した HTTP リクエストメソッド。 |
| cs-uri-stem | path(例:/api/aaa) |
| sc-status | サーバーのレスポンスの HTTP ステータスコード(例: 200) |
| cs-uri-query | リクエスト URL のクエリ文字列の部分 (ある場合)。ない場合は- |
| x-edge-result-type | サーバーが、最後のバイトを渡した後で、レスポンスを分類した方法。 |
| time-to-first-byte | サーバー上で測定される、要求を受信してから応答の最初のバイトを書き込むまでの秒数。 |
その他の詳細についてはドキュメントを参照して下さい。 標準ログ (アクセスログ) の設定および使用 - Amazon CloudFront
分析までの手順
正しくデータを読み込む
CloudFrontのデータの形式が1行目が#Version: 1.0、2行目が#Fields: date time x-edge-location ...となっており正しくフィールド名を当てられません。このため、3行目以降を読み込むようにしてフィールド名は手動であてました。
def read_csv(path): df = pd.read_csv(path, sep='\t', skiprows=[0,1], header=None) df.columns = [ "date", "time", "x-edge-location", "sc-bytes", "c-ip", "cs-method", "cs(Host)", "cs-uri-stem", "sc-status", "cs(Referer)", "cs(User-Agent)", "cs-uri-query", "cs(Cookie)", "x-edge-result-type", "x-edge-request-id", "x-host-header", "cs-protocol", "cs-bytes", "time-taken", "x-forwarded-for", "ssl-protocol", "ssl-cipher", "x-edge-response-result-type", "cs-protocol-version", "fle-status", "fle-encrypted-fields", "c-port", "time-to-first-byte", "x-edge-detailed-result-type", "sc-content-type", "sc-content-len", "sc-range-start", "sc-range-end" ] return df
学習できる形式に変換
読み込んだDataFrameはそのままでは学習できないので数値に変換して学習できる形式に変換します。
method, result_type, path_num, path_0, path_1, path_2, path_3, path_4, query_num, query_len, sc-status, time-to-first-byteの12個の数値データを持つDataFrameに変換していきます。
method
メソッドの種類を数字に割り当てます。例えばGET:0、POST:1みたいな。factorizeというメソッドを使いました(データ量多いと遅くなりそうだが1万行くらいのデータ数であれば特に問題なかったです)
result_type
x-edge-result-typeで返ってくる文字列を数字に割り当てます。例えばHIT:0、MISS:1、ERROR:2。こちらもfactorize使ってます。
path_num
pathの深さ。例えば/api/aaaだったら2、/api/aaa/bbbだったら3を入れています。
path_0 ~ path_4
pathの深さごとのリソース名を数値に割り当てます。
例えば/api/aaa/bbbというpathと/api/aaa/cccがあった場合。/aaa/bbb/はpath_0:0、path_1:0、/aaa/cccはpath_0:0、path_1:1の様になります。
query_num
付与されているクエリパラメータの数
query_len
付与されているクエリパラメータの文字列の長さ
sc-status
ステータスコード(CFのログデータをそのまま使用)
time-to-first-byte
レスポンスまでにかかった時間(CFのログデータをそのまま使用)
この様に変換した上で学習に使用するフィールドだけにします。
def convert_df(df_orig): df = df_orig[["cs-method", "cs-uri-stem", "sc-status", "cs-uri-query", "x-edge-result-type", "time-to-first-byte"]] df["method"] = df["cs-method"].factorize()[0] df["result_type"] = df["x-edge-result-type"].factorize()[0] split_path = df["cs-uri-stem"].str.strip("/").str.split("/") df["path_num"] = split_path.str.len() df["path_0"] = split_path.str[0].factorize()[0] df["path_1"] = split_path.str[1].factorize()[0] df["path_2"] = split_path.str[2].factorize()[0] df["path_3"] = split_path.str[3].factorize()[0] df["path_4"] = split_path.str[4].factorize()[0] df["query_num"] = df["cs-uri-query"].str.split("&").str.len() df["query_len"] = df["cs-uri-query"].str.len() df = df[["method", "path_num", "path_0", "path_1", "path_2", "path_3", "path_4", "query_num", "query_len", "sc-status", "time-to-first-byte"]] return df
学習
IsolationForestを用いて学習させます。anomaly_labelには正常の場合1、異常の場合-1が入ります。
model = IsolationForest(n_estimators=300, contamination="auto", random_state=123) model.fit(df) df["anomaly_label"] = model.predict(df)
元のデータと結合
学習した結果データは数字だけになっていて見づらいので元のデータを結合して確認しやすくしています。
df_data = df_orig[["cs-method", "cs-uri-stem", "cs-uri-query", "x-edge-result-type", "sc-content-len"]] df_cat = pd.concat([df, df_data], axis=1)
CSVファイルに出力
結果を見るために今回はCSVファイルに出力しています。
output = os.path.join('/content/drive/MyDrive/dev/', 'output.csv') df_cat.to_csv(output, index=False)
コード全体
これまでの処理の流れをまとめると以下の様になります。
import os import pandas as pd from sklearn.ensemble import IsolationForest # CFログを読み込んでDataFrameに変換 def read_csv(path): df = pd.read_csv(path, sep='\t', skiprows=[0,1], header=None) df.columns = [ "date", "time", "x-edge-location", "sc-bytes", "c-ip", "cs-method", "cs(Host)", "cs-uri-stem", "sc-status", "cs(Referer)", "cs(User-Agent)", "cs-uri-query", "cs(Cookie)", "x-edge-result-type", "x-edge-request-id", "x-host-header", "cs-protocol", "cs-bytes", "time-taken", "x-forwarded-for", "ssl-protocol", "ssl-cipher", "x-edge-response-result-type", "cs-protocol-version", "fle-status", "fle-encrypted-fields", "c-port", "time-to-first-byte", "x-edge-detailed-result-type", "sc-content-type", "sc-content-len", "sc-range-start", "sc-range-end" ] return df # 学習できる形式にDataFrameを変換します def convert_df(df_orig): df = df_orig[["cs-method", "cs-uri-stem", "sc-status", "cs-uri-query", "x-edge-result-type", "time-to-first-byte"]] df["method"] = df["cs-method"].factorize()[0] df["result_type"] = df["x-edge-result-type"].factorize()[0] split_path = df["cs-uri-stem"].str.strip("/").str.split("/") df["path_num"] = split_path.str.len() df["path_0"] = split_path.str[0].factorize()[0] df["path_1"] = split_path.str[1].factorize()[0] df["path_2"] = split_path.str[2].factorize()[0] df["path_3"] = split_path.str[3].factorize()[0] df["path_4"] = split_path.str[4].factorize()[0] df["query_num"] = df["cs-uri-query"].str.split("&").str.len() df["query_len"] = df["cs-uri-query"].str.len() df = df[["method", "path_num", "path_0", "path_1", "path_2", "path_3", "path_4", "query_num", "query_len", "sc-status", "time-to-first-byte"]] return df # ファイルの読み込み df_orig = read_csv("/content/drive/MyDrive/dev/EEEEEEEEEEEEEE.2023-12-07-01.aaaaaaaa.gz") file_names = [ "EEEEEEEEEEEEEE.2023-12-07-01.bbbbbbbb.gz", "EEEEEEEEEEEEEE.2023-12-07-01.cccccccc.gz", "EEEEEEEEEEEEEE.2023-12-07-dddddddd.gz", "EEEEEEEEEEEEEE.2023-12-07-01.eeeeeeee.gz", "EEEEEEEEEEEEEE.2023-12-07-01.ffffffff.gz", "EEEEEEEEEEEEEE.2023-12-07-00.gggggggg.gz", "EEEEEEEEEEEEEE.2023-12-07-01.hhhhhhh.gz", "EEEEEEEEEEEEEE.2023-12-07-01.iiiiiiii.gz", "EEEEEEEEEEEEEE.2023-12-07-01.jjjjjjjj.gz", "EEEEEEEEEEEEEE.2023-12-07-01.kkkkkkkk.gz", "EEEEEEEEEEEEEE.2023-12-07-02.llllllll.gz" ] for fname in file_names: df_orig = pd.concat([df_orig, read_csv(f"/content/drive/MyDrive/dev/{fname}")]) # 学習できる形式に変換 df = convert_df(df_orig) # 学習させる model = IsolationForest(n_estimators=300, contamination="auto", random_state=123) model.fit(df) df["anomaly_label"] = model.predict(df) # 結果が見づらいので元のデータと結合 df_data = df_orig[["cs-method", "cs-uri-stem", "cs-uri-query", "x-edge-result-type", "sc-content-len"]] df_cat = pd.concat([df, df_data], axis=1) # CSVファイルに出力 output = os.path.join('/content/drive/MyDrive/dev/', 'output.csv') df_cat.to_csv(output, index=False)
分析結果
当初の想定通りpathごとに異常値が検出されているのか確認してみました。
(比較的)うまくいった結果
419回のリクエストに対して異常値のリクエストが8回と1.9%が異常値となりました。異常値のデータと正常値のデータの一部を抜き出してみると下記のようになりました。
| method | path_num | path_0 | path_1 | path_2 | path_3 | path_4 | query_num | query_len | sc-status | time-to-first-byte | anomaly_label | cs-method | cs-uri-stem | cs-uri-query | x-edge-result-type | sc-content-len |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 3.149 | -1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 0 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 1.98 | -1 | OPTIONS | /api/aaa/bbb/ | - | Miss | 0 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 3.927 | -1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 2.128 | -1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 2.373 | -1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 1.931 | -1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 2.02 | -1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 0 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.082 | -1 | OPTIONS | /api/aaa/bbb/ | - | Miss | 0 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.339 | 1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.348 | 1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.348 | 1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.342 | 1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.374 | 1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.357 | 1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
| 1 | 3 | 0 | 0 | 8 | -1 | -1 | 1 | 1 | 200 | 0.345 | 1 | POST | /api/aaa/bbb/ | - | Miss | 47 |
ちょっとまだ見づらいので関係がありそうなフィールドのみが見えるようにした上でtime-to-first-byteで並び替えて、メソッドもPOSTとOPTIONSそれぞれで比較していきます。
まず、POSTについては
| time-to-first-byte | anomaly_label | cs-method | cs-uri-stem |
|---|---|---|---|
| 3.927 | -1 | POST | /api/aaa/bbb/ |
| 3.149 | -1 | POST | /api/aaa/bbb/ |
| 2.373 | -1 | POST | /api/aaa/bbb/ |
| 2.128 | -1 | POST | /api/aaa/bbb/ |
| 2.02 | -1 | POST | /api/aaa/bbb/ |
| 1.931 | -1 | POST | /api/aaa/bbb/ |
| 1.324 | 1 | POST | /api/aaa/bbb/ |
| 1.31 | 1 | POST | /api/aaa/bbb/ |
| 1.138 | 1 | POST | /api/aaa/bbb/ |
| 0.983 | 1 | POST | /api/aaa/bbb/ |
| 0.96 | 1 | POST | /api/aaa/bbb/ |
| 0.862 | 1 | POST | /api/aaa/bbb/ |
time-to-first-byteで並び替えてみると異常値と正常値の差があまりなくなってしまっていますが、1.931と1.324の間あたりで異常値と正常値が変わっている様に見えます。
割合で表すと異常値の割合が1.75%、グラフで表すと左の赤枠内の部分が異常値となっています。
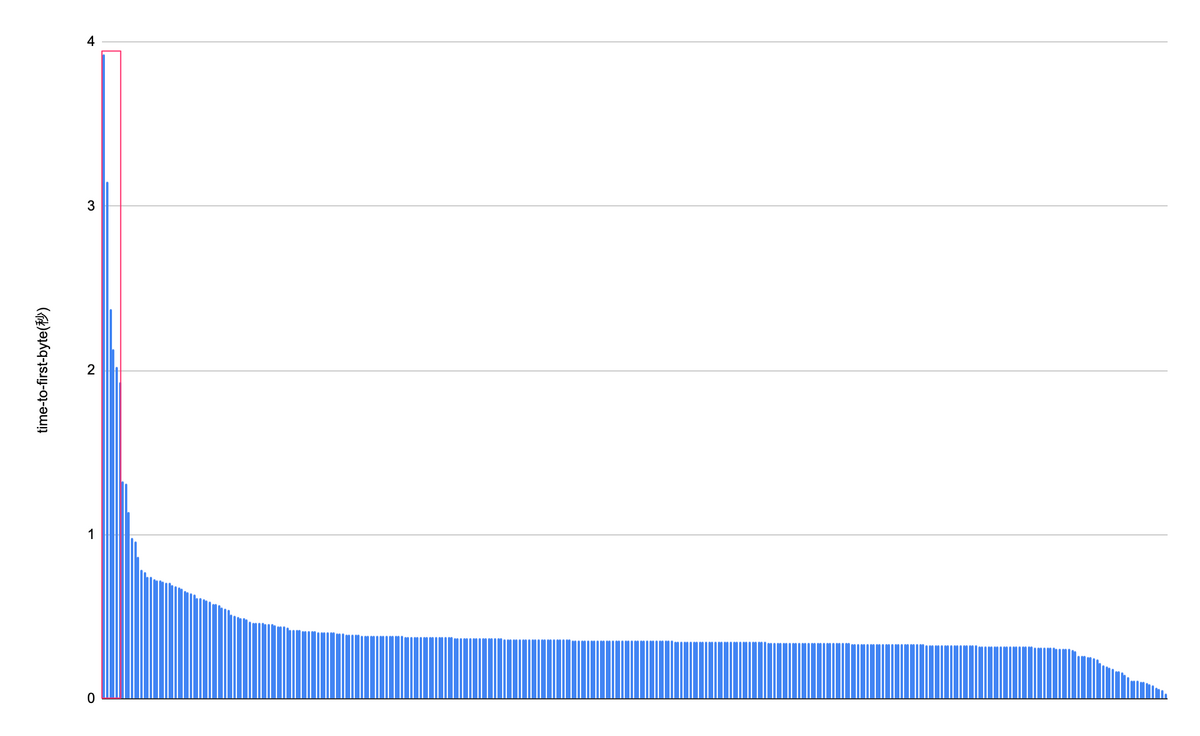
OPTIONSについては
| time-to-first-byte | anomaly_label | cs-method | cs-uri-stem |
|---|---|---|---|
| 1.98 | -1 | OPTIONS | /api/aaa/bbb/ |
| 0.082 | -1 | OPTIONS | /api/aaa/bbb/ |
| 0.061 | 1 | OPTIONS | /api/aaa/bbb/ |
| 0.051 | 1 | OPTIONS | /api/aaa/bbb/ |
| 0.025 | 1 | OPTIONS | /api/aaa/bbb/ |
| 0.02 | 1 | OPTIONS | /api/aaa/bbb/ |
| 0.017 | 1 | OPTIONS | /api/aaa/bbb/ |
0.082と0.061の間で異常値と正常値が変わっている様に見えます。異常値の割合は2.78%、グラフで表すと以下の様になりました。
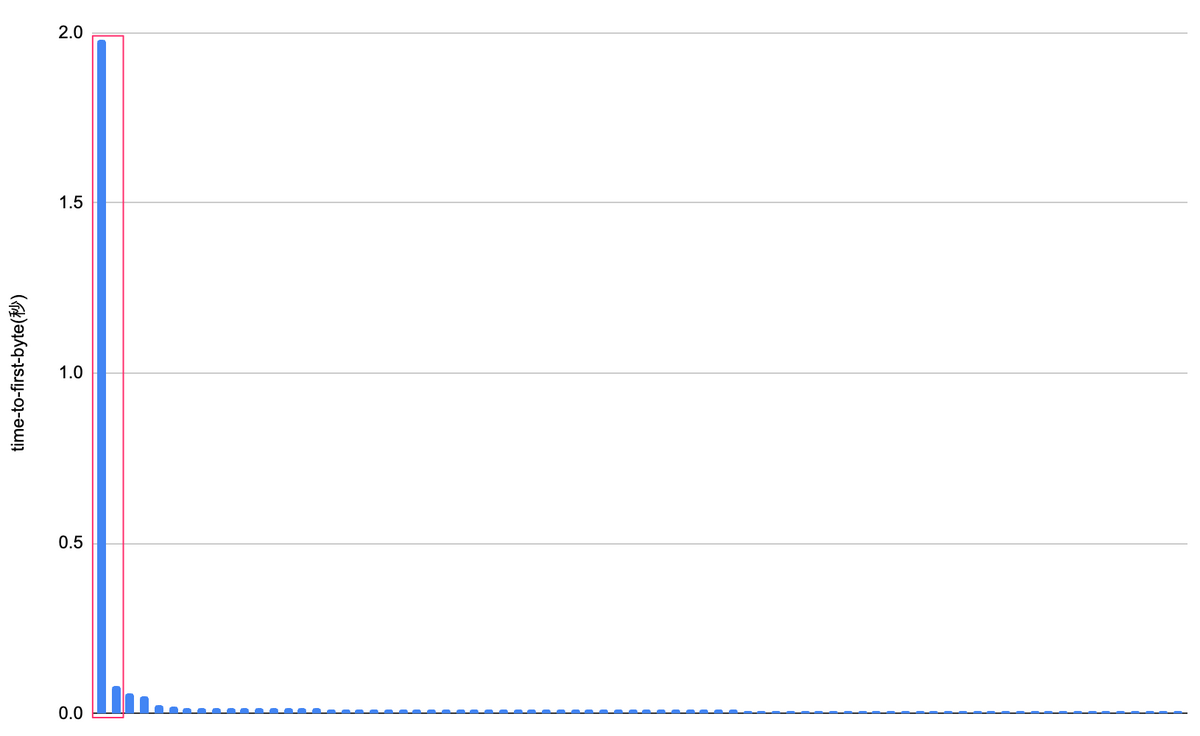
うまくいかなかった結果
認証のリクエストなどですべてが異常値になってしまっているものがありました。傾向としては全体のリクエスト数に対して少ししか叩かれないようなリクエストが全て異常値となってしまっている様でした。
参照したサイト
まとめ
結果としては、この異常値をそのまま使うというよりかは異常値判定されているリクエストを元に当てをつけて調べたりとかは出来そうかなという感じでした。また、学習させる際の数値(ベクトル)データの作り方やパラメータの調整や特定のpathだけに絞った上で学習させてみるなど改善方法はまだまだありそうです。
最後に
最後まで読んでくださりありがとうございます!
この記事を読んで興味を持って下さった方がいらっしゃればカジュアルにお話させていただきたく、是非ご応募をお願いします! Wantedly / Green
次回は複雑な仕様もすぐキャッチアップして驚異的な気付き力でどんどんサービスを改善していってくれている腰丸さんです!どんな記事か楽しみです!