こんにちは、iimonでエンジニアをしている須藤です。 今回は、AWSのdocumentを読んでいて、ベクターストアという記述があり気になったので調べてみました。
ベクトルデータベースとは
 (https://qdrant.tech/articles_data/what-is-a-vector-database/Why-Use-Vector-Database.jpg)
(https://qdrant.tech/articles_data/what-is-a-vector-database/Why-Use-Vector-Database.jpg)
{kind=link}
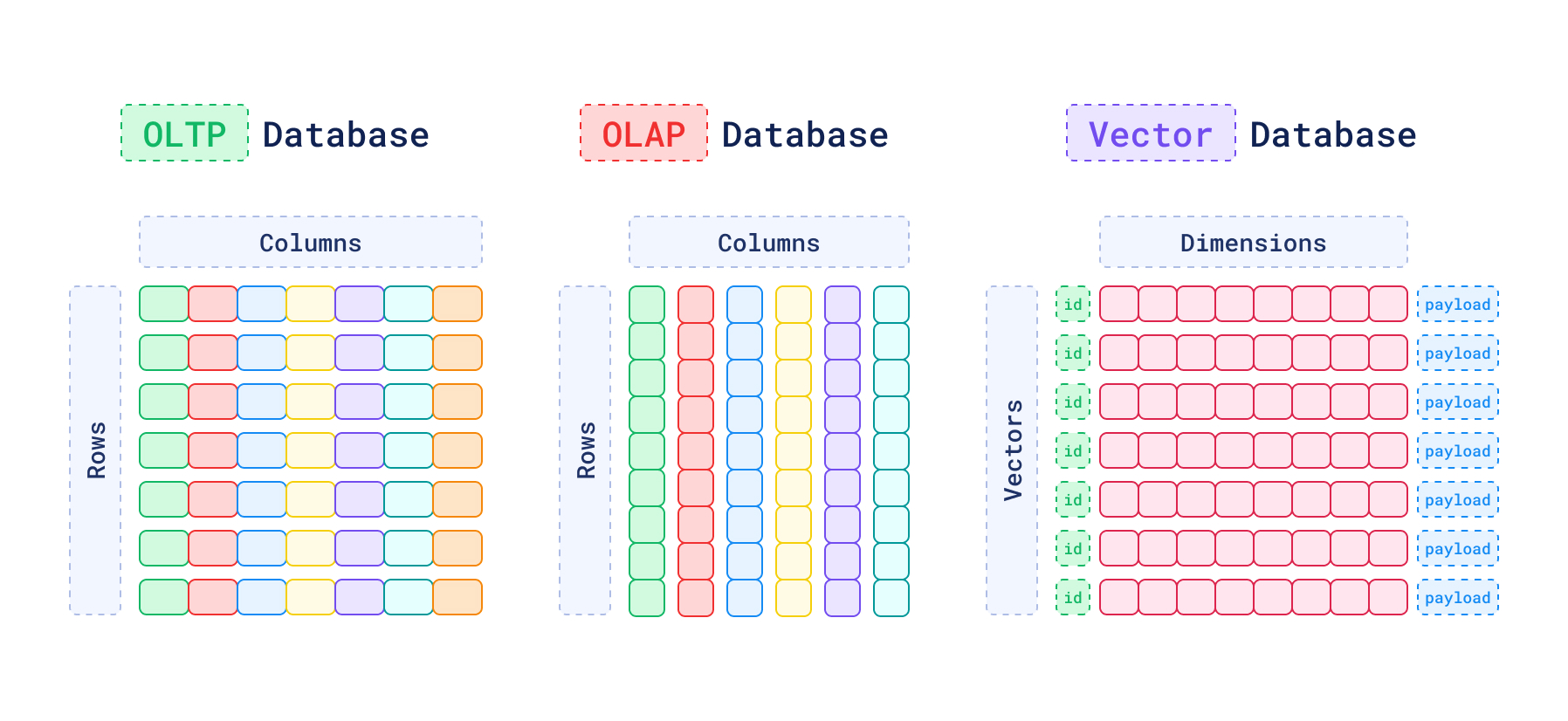
データを高次元ベクトル(大きさと向きを持った量)として保存、管理するデータベースのこと。
例えば、特定の画像に人間30%, アニメ3%, スポーツ4%, 交通20%, ...の特徴が含まれているとき、[0.3, 0.03, 0.04, 0.2, ...]のような数値の配列形式でベクトルを表し、保存されたベクトルと検索するクエリベクトル間の距離の比較により類似性検索を行います
従来のスカラーデータベースでは「films」と「movies」など意味が似ていても単語が異なると検索にマッチしないなど、微妙なニュアンスや意味に基づいて検索するのが難しかったが、ベクトルデータベースでは意味的に近い単語は近く配置されるので、意味に基づく類似検索を行うことができるようになります
ベクトル化について
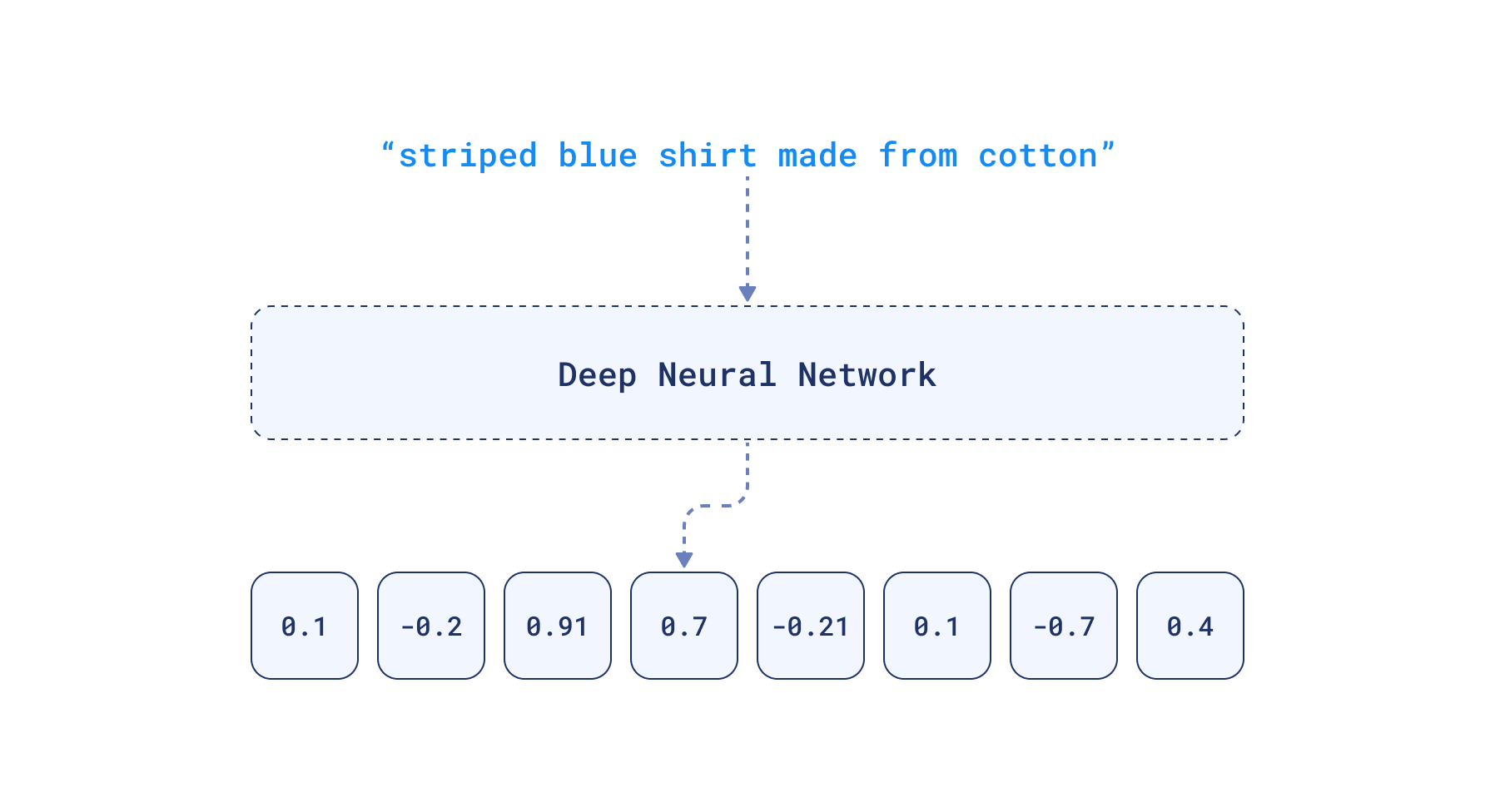
非構造化データをモデルに入力することで、類似した項目が近くに配置され、それらのベクトルは"embeddings"(埋め込み表現)と呼ばれる高次元ベクトルとして表現されます

(https://qdrant.tech/articles_data/what-is-a-vector-database/Vector-Data.jpg)
{kind=link}
ベクトル化に利用するモデルと概要
ドキュメントベースのモデル(意味的関連性)
bag-of-words(文章を単語に分けて順序関係なしに袋に詰めるイメージ)

(https://miro.medium.com/v2/resize:fit:720/format:webp/1*axffCQ9ae0FHXxhuy66FbA.png)
{kind=link}
- 文章を単語に分割して、単語と出現頻度を下に文章をベクトル化する教師なしの学習方法
- 人の手でラベルをつける(アノテーションする)と文書分類に利用することができる
- 幅広いトピック性は捉える事はできるが、複雑な構文や意味などは捉えることができない
- 文章から得られるすべての特徴を含めるとサイズが大きくなるので前処理が必要になる(例 iimonをiimonに統一するとか)
- TF-IDF(term frequency–inverse document frequency)
- “その”、”この”、”。”など一般的な単語の重みを小さくすることでbag-of-wordsに重要度を反映することができる
LSA、PLSA、LDA(トピックモデル)
- 文書やテキストデータが特定のトピックに基づいて生成されるという仮定に基づいている
- 文書とトピックの間の潜在要因を仮定してクラスタリングを行う手法、使われ方が似ている単語を集約することで5000 * 10000のデータを5000 * 5という低次元データで説明(次元圧縮)することができる
- 最終的に文章は複数のトピックの割合として表現される(ソフトクラスタリング) (例 [政治:30%, 経済10%, スポーツ5%]) (LSAは事前のbag-of-wordsやtf-idfによる重み付けが必要で、それを確率処理することで重み付けを必要なくしたのがPLSA、新規のデータの性能が悪い問題(過学習)に対応したのがLDAで、学習後新たなデータを学習無しで処理できる)
ニューラルネットワークを用いたアプローチ
word2vec(単語の意味を考慮できるモデル、意味的類似性)
- 分布仮説という文章中の単語の意味は周囲の単語によって形成されるという仮説に基づいている
- 文章を3つの単語からなるグループに分けて、周囲の単語に基づいて中心の単語を予測する層(cbow)と逆に中心の単語に基づいて周囲の単語を予測する層(skip-gram)がからなるニューラルネットワーク
- 例えばthe cat sat on the matという文字列を三単語ずつグループ化(the cat sat)してそれらの単語のベクトルを潜在空間内で少しずつ近づけるという方法
- 十分なトレーニングデータがあれば単語ベクトルが意味の類似性や加法構成性をもつようになる(例 king - man + woman = queenが成り立つ)
- 単語の意味を考慮できるようになったことで、機械翻訳やレコメンドシステムに使われていた 足し合わせロジックを利用してユーザーの志向を捉えることができたという事例もあります(リクルート式 自然言語処理技術の適応事例紹介 | PPT)
RNN(リカレントニューラルネットワーク)
シーケンシャルな依存関係を捉えるモデル

(https://chefyushima.com/wp-content/uploads/2023/05/image-4-1024x333.png)
{kind=link}
- 一部のノードからの出力が同じノードへの後続の入力に影響を与える
- 情報が増えると、複雑になりすぎて重要な情報が消える(勾配消失問題)問題があり、長期の依存関係を捉えるのが難しくなることがある
- テキスト分類、テキスト生成、感情分析、機械翻訳、信号処理、音声認識、動画や画像分析などに利用される
LSTM(長・短期記憶)
 (https://cvml-expertguide.net/wp-content/uploads/2021/09/LSTM-3gates.png)
(https://cvml-expertguide.net/wp-content/uploads/2021/09/LSTM-3gates.png)
{kind=link}
- RNNの勾配消失問題に対処するために短期記憶と長期記憶の信号を分けて扱い、不要な情報を忘却ゲートで消すようにした方法
- 関連情報をいつ記憶し、いつ忘れるかを学習させている
- 逐次的にデータを処理する必要があり大きなボトルネックになっている
Transformer

(https://www.nomuyu.com/wp-content/uploads/2023/12/Pasted-6.png)
{kind=link}
- “self-attension”レイヤーを利用していて、「コップがある、それは透明だ」という文章の「それ」がコップを示すこと学習することができて 単語間の距離に関係なく依存関係を学習できる
- 逐次的に処理しなくても位置エンコードを利用することで位置による依存関係も学んでくれる
- 再帰型や畳込み型に比べて計算効率が高く、並列計算が可能
- エンコーダでベクトル化している
- 自己教師あり学習(穴埋め問題など)で文章を予測するために文脈や背景知識を勝手に学んでくれる
- GPTなどのLLMで利用されている
単語の出現回数、文章のトピック、単語の意味、文章の意味から文脈とベクトルで抽象的な内容が表現可能になっていることがわかるかと思います。
検索について
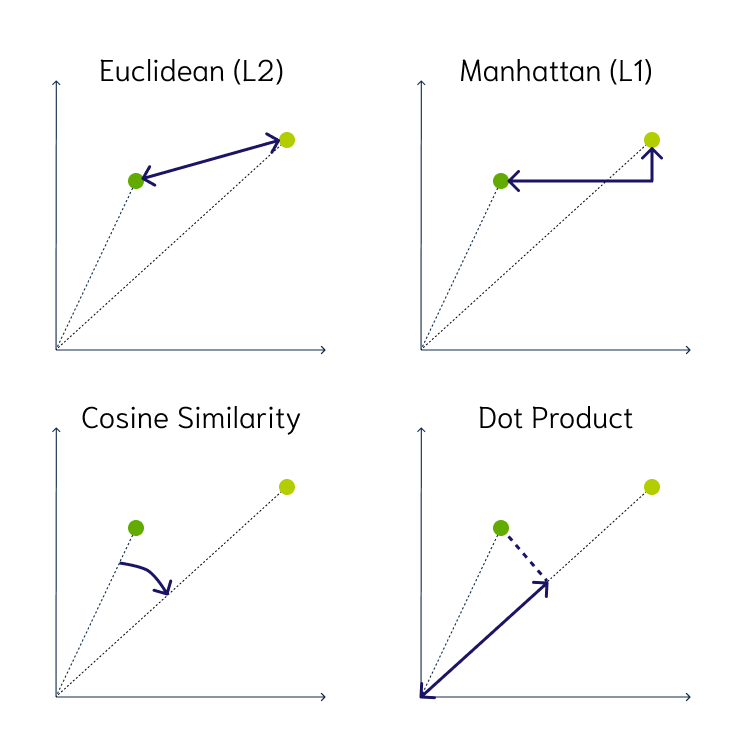
ベクトルの作成に利用したモデルを利用して検索内容(クエリ)をベクトル化すると、近い意味を持つベクトルは距離的に近くなり、最近傍(さいきんぼう)点を計算できればその内容を取得することできます。

(https://weaviate.io/assets/images/similarity-measures-058e10fc2cabc583ba953d42d14c2b4b.jpg)
{kind=link}
計算する方法としてコサイン類似度や最大内積探索、ユークリッド距離、Manhattan距離(すべての次元の絶対値の差の合計)がありますが、ベクトル同士を一つ一つ比較していては計算量が莫大になるので近似最近傍 (ANN) 探索と呼ばれる近くの点を検索するアルゴリズムが利用されます
近似最近傍探索関連の技術
HNSW(Hierarchical Navigable Small Worlds)アルゴリズム

{kind=link}
- すべてのベクトルが含まれる最下層とその中のランダムなサブセットが含まれる上位層というのが繰り返される形でグラフが構築され、検索時は最上位のベクトルから走査して、最近傍点を見つけたら下の層へ移動し、再度走査というのを最下層に到達するまで繰り返す。学習が必要ない。
- よって効率的に探索できレイテンシが少なく、近似精度の高い検索が可能なインデックスと言われています
- ベクトル毎にエッジの集合を保存しているのでメモリ使用率が多いというデメリットがある
IVF(転置ファイルシステム)アルゴリズム

{kind=link}
- K-Meansクラスタリングにより(=学習あり)それぞれのクラスタのセントロイド(重心)を代表ベクトルに決定し、クラスタごとにバケットを分けて保存することで、検索時は代表ベクトルから検索することで検索時間を削減することができる
- HNSWと比べるとメモリの節約に優れている
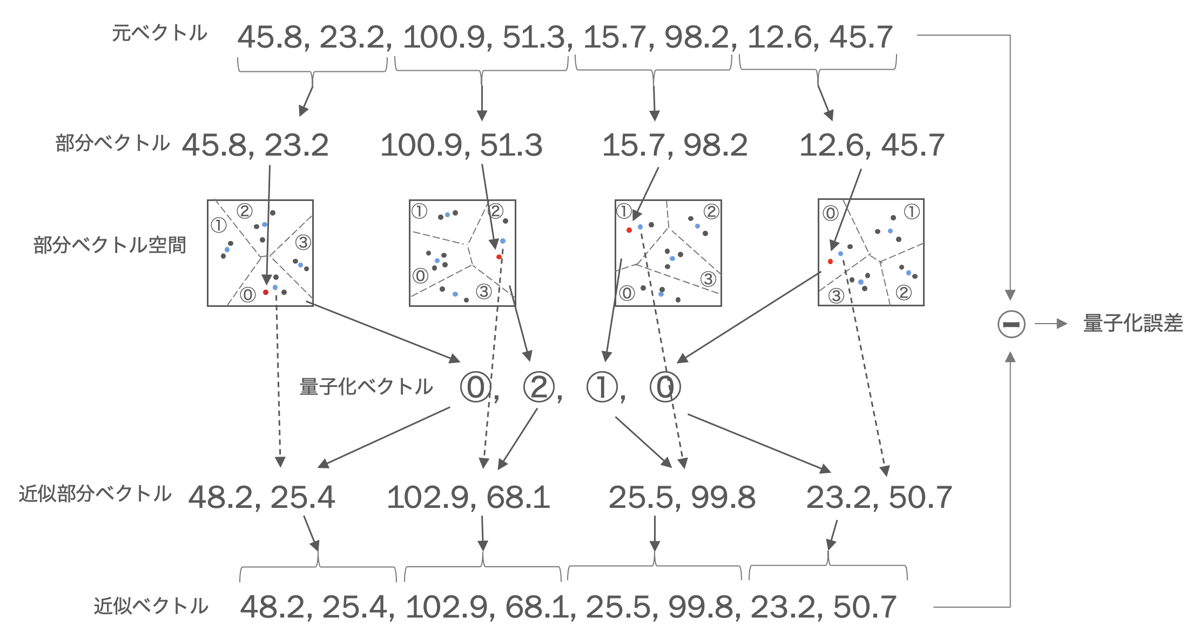
PQ(直積量子化)ベクトル圧縮
 (https://s.yimg.jp/images/tecblog/2022-H2/262/02_product_quantization.png)
(https://s.yimg.jp/images/tecblog/2022-H2/262/02_product_quantization.png)
{kind=link}
- ここで量子化というのは、ベクトルをよりデータサイズの小さな空間にマッピングすること ([10.1, 2.3]を0とするようなもの)
- 高次元ベクトルを均等に分割し、分割された先頭のベクトルに対してそれぞれK-meansクラスタリングを行うことでセントロイドIDを割り当て符号化する、これを分割した回数繰り返すという方法、検索時はクエリを量子化して探索を行う
- 学習時に各クラスタの重心点をまとめたコードブックを作成し、復号化時はCentroidIDを利用して代表ベクトル取り出すことでベクトルを近似的に再構成することもできる
- メモリを大幅に節約することができるが、再現率が低く、IVFと組み合わせてIVFPQとして利用されることが多い
HNSWとIVFPQのレイテンシ、メモリ消費量の違いがよく分かる実験資料(OpenSearch における 10 億規模のユースケースに適した k-NN アルゴリズムの選定 | Amazon Web Services ブログ)

その他
- RAGを構成することで生成AIで自社のデータを含めた検索を可能にしたり、特定の知識に強化しハルシネーションを防いだりと、生成AIモデルにデータを供給する際にもベクトルデータベースが利用されている
- 製品としてはベクトルネイティブ系(Pinecone, Qdrant)、rdbms系(PostgreSQLのpgvector)、全文検索系(Elasticsearch)などがある
- キーワード検索とセマンティック検索の両方を実行できるハイブリット検索ができるものもある
まとめ
ベクトルデータベースやLLMとの関係性やインデックス手法について学ぶことができました。
また、今回はあまりできませんでしたが、ニューラルネットワークを数式から理解したり、計算の並列化や最適化に使われる技術、マルチモーダルの仕組みについて調べるのも面白そうだと感じました。
間違った内容やニュアンスの異なる表現がございましたらご指摘よろしくお願いします。
また、弊社ではエンジニアを募集しております。
ぜひカジュアル面談でお話ししましょう!
ご興味ありましたら、ご応募ください!
参照情報
What is a Vector Database? - Qdrant
PLSA(確率的潜在意味解析) | 株式会社アナリティクスデザインラボ
Hierarchical Navigable Small Worlds (HNSW) | Pinecone
OpenSearch における 10 億規模のユースケースに適した k-NN アルゴリズムの選定 | Amazon Web Services ブログ
直積量子化とグラフを融合し、ベクトル近傍検索のボトルネックを改善する(NGTのインデックスQGの紹介) - Yahoo! JAPAN Tech Blog