こんにちは、iimonでエンジニアをしている須藤です。 今回は、redshiftのdocを読んでいて、列指向ストレージという記述があり、行指向との違いが気になったので調べてみることにしました。
行指向と列指向(columnar)の比較
データの格納方式の違い(定義)
普段使っているMySQLやPostgreSQLなどのRDBMSは、行指向のデータベースで、下の図のように、行ごとにブロックを作成し保存しています。
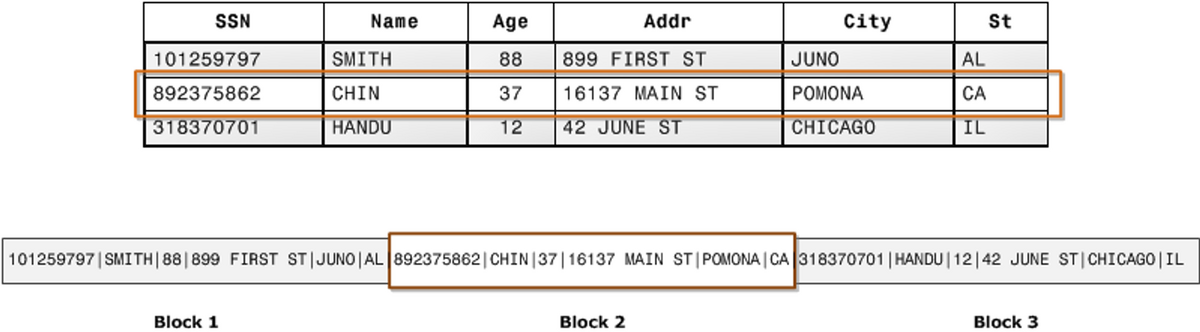
それに対して、列指向のデータベース・DWH(Redshift, Snowflake, BigQuery, Apache Cassandraなど)では列ごとにブロックを作成し保存しています。
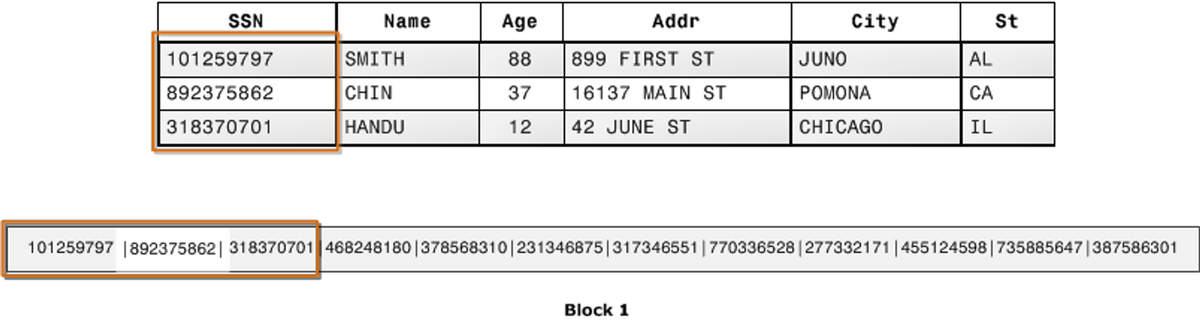
データの圧縮効率
列指向の場合は、上の図で数字が並んでいるように同じ型の似たデータが並ぶことが多いので、圧縮効率が列指向より良いという特徴があります。
集計時の検索効率
例えば下のようなクエリがあったとき
SELECT SUM(price) FROM table1;
行指向データベースでは、一行ずつ、ほとんど又は、すべてのカラムを無駄に読み込んで、特定の列の値を計算していきます。
それに対して、列指向データベースでは、計算に必要なデータ(カラム)のみを読み込み計算していきます。
よって、I/O操作が節約され、クエリのパフォーマンスが最適化されます。
また、この効果はtableの列数や行数に比例して大きくなります。
データの更新のコスト
一件のデータの追加・更新・削除する場合、列指向データベースでは、分かれたブロックのすべての列の更新が必要になり、またデータの再圧縮も必要になるので、実行コストが高くなります。
逆に行指向のMySQLは一つのブロックを更新するだけなので、より低いコストで更新することができます。
用途
以上の特徴から分かる通り基本的に用途は分かれており、リアルタイムの高速なトランザクション処理が必要な場合には行指向データベース、大量のデータを分析するような場合には列指向のデータベースが向いているといると思います。
また、行指向データベースで集計の計算ができないわけでもないので、パフォーマンスとコストを比較しながら選定する必要がありそうです。
関連する技術
圧縮エンコーディング
先ほど、列指向のメリットで紹介した列ごとの圧縮に利用されている技術
代表的なものにランレングスエンコーディングと辞書エンコーディングというものがあります。
- ランレングスエンコーディング
連続で繰り返される値を、連続する値と出現回数をもったディクショナリーに置き換える方法で、連続しているほど圧縮できるのでsortされたカラムに対して効果的なことがわかります。
変換前
| c1 | c2 | c3 |
|---|---|---|
| a | 2 | z |
| a | 2 | x |
| a | 1 | x |
| b | 1 | x |
| b | 1 | y |
| b | 3 | y |
| b | 3 | z |
変換後
| c1 | c2 | c3 |
|---|---|---|
| (3, a) | (2, 2) | (1, z) |
| (4, b) | (3, 1) | (3, x) |
| (2, 3) | (2, y) | |
| (1, z) |
- 辞書エンコーディング
一意の値ごとの辞書を作成し、インデックスとして保存される1バイトの値に置き換えられるという方法で、1バイトで表すことができる256個未満のカーディナリティーが低い文字列に対して有効な方法になります。
辞書
| イングランド | 0 |
|---|---|
| アメリカ合衆国 | 1 |
| ベネズエラ | 2 |
| スリランカ | 3 |
| アルゼンチン | 4 |
| 日本 | 5 |
変換前
| イングランド |
|---|
| イングランド |
| アメリカ合衆国 |
| アメリカ合衆国 |
| ベネズエラ |
| スリランカ |
| アルゼンチン |
| 日本 |
| スリランカ |
| アルゼンチン |
変換後
| 0 |
|---|
| 0 |
| 1 |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 3 |
| 4 |
他にもたくさんの圧縮方法がありますが、行指向と比較した際、列指向のデータの方が圧縮効率が高くなりそうなのはわかるかと思います。
列指向のデータファイル形式
有名なものに、Apache Parquet (Athenaでも利用されている)
行グループの中に列指向形式でデータが保存されています。
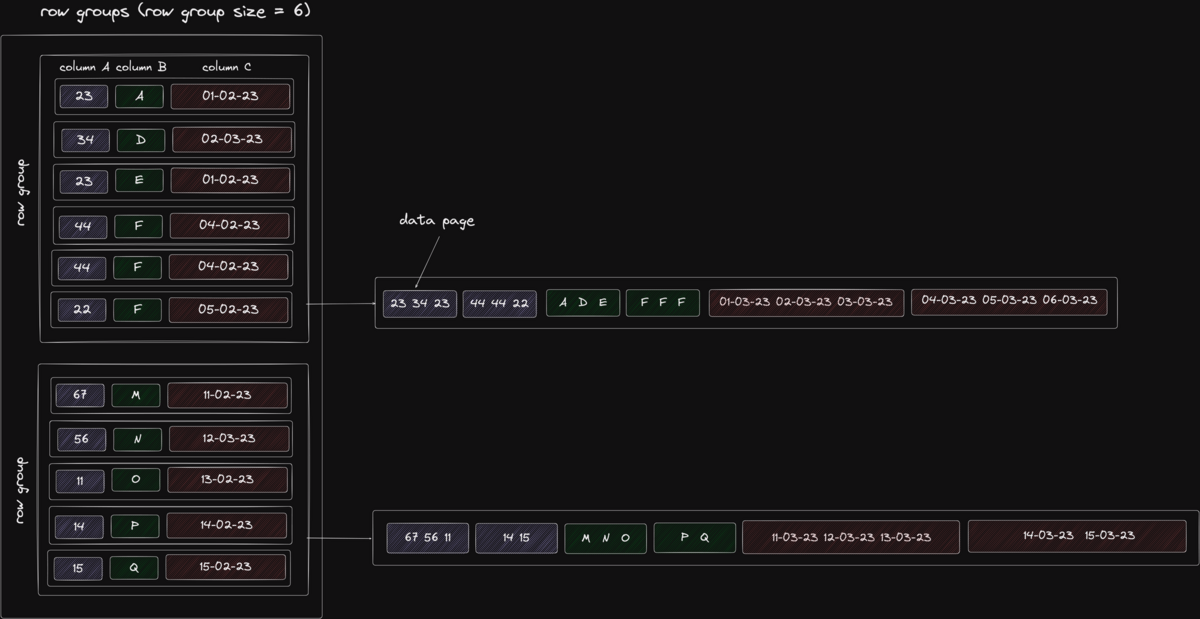
また自己記述形式のメタ情報として、スキーマ、圧縮設定、値の数、列の位置、最大値最小値、行グループの数、データへの参照などがあり、
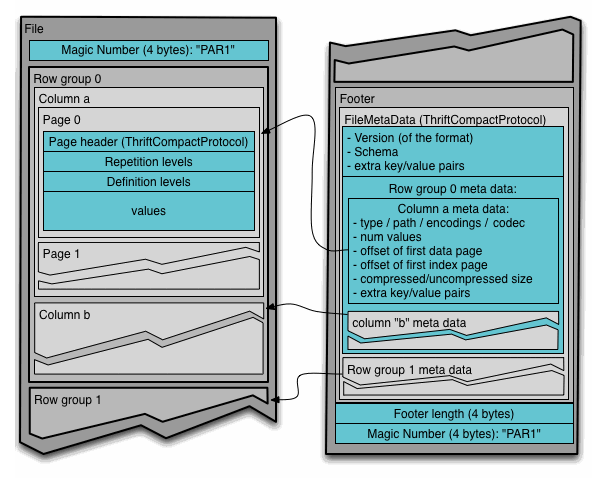
それらを利用した、プレディケイトプッシュダウンと呼ばれる、WHERE句やGROUP BY句を効率的に処理するためにRow groupレベルでのスキップが行われることにより、I/O操作が最適化されます。
(例) column1の値が250以上のcolomn2の値を取得するクエリ
row group1のメタデータ: colomn1の最小値100、最大値200 colomn1: 100, 150, 200 colomn2: a, b, c
row group2のメタデータ: colomn1の最小値200、最大値300 colomn1: 200, 250, 300 colomn2: d, e, f
row group1はmeta情報を見て読み込みがスキップされる
まとめ
今回は列指向と行指向を分けながら特徴や周辺技術について理解していきましたが、 列指向と行指向を併用できるTiDBのTiFlashやあまり触れたことのないAWS EMR、parquetのパフォーマンスチューニングなど面白そうなことを知れたので調べてみたいなと思いました。
また、今回調べた内容で間違いや発展的内容がありましたら、コメントをお待ちしております。
iimonではエンジニアを募集しています。カジュアルからでもお話させていただきたく、是非ご応募していただけると嬉しいです!
参照情報
列指向について
https://docs.aws.amazon.com/redshift/latest/dg/c_columnar_storage_disk_mem_mgmnt.html
https://docs.treasuredata.com/pages/releaseview.action?pageId=331325
https://www.publickey1.jp/blog/13/_1.html
parquetについて
https://parquet.apache.org/docs/file-format/
https://clickhouse.com/blog/apache-parquet-clickhouse-local-querying-writing-internals-row-groups
https://aws.amazon.com/jp/blogs/news/top-10-performance-tuning-tips-for-amazon-athena/ parquetのパフォーマンスチューニング
encodingについて https://cloud.google.com/blog/products/bigquery/inside-capacitor-bigquerys-next-generation-columnar-storage-format?hl=en https://docs.aws.amazon.com/redshift/latest/dg/c_Byte_dictionary_encoding.html