トレースとは・・・3つの主要な可観測性の柱の1つとされていて、複数のコンポーネントにまたがるリクエストの流れや処理を把握するために使用されるもの
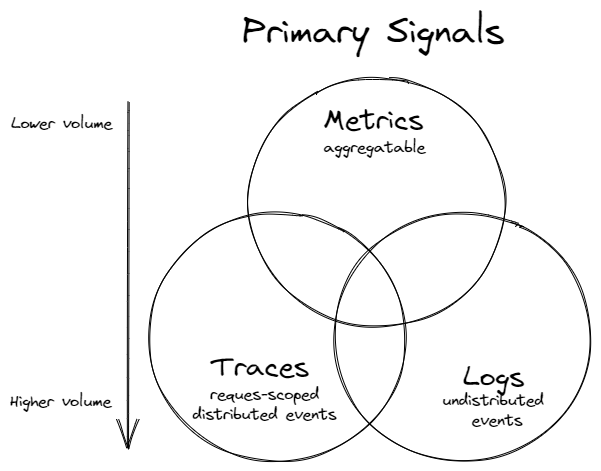
まずは全体像を掴むために他の2つのテレメトリタイプ(送信収集されるデータのタイプ)も含めて簡単なおさらい
3つの主要な柱
メトリクス


特定の時間におけるcpu、memoryの使用率といったリソースの使用状況と2xx系のstatus codeの数、リクエスト数といったサービスの稼働状況を測定するための数値データで時間軸集計される
なにが起こっているかを知ることができる
ログ
Server, OS, アプリケーションなどの動作や状態を説明するテキスト情報のストリーム
アプリケーションやシステムの状態の詳細を理解するのに役立つ
トレース(分散トレーシング)

単一のリクエストに対する複数サービスにまたがる分散したトランザクションの追跡を行う
あるリクエストに対して内部で呼び出されているservice、その応答時間やレイテンシの計測、service間の依存関係のリアルタイムな視覚化に利用できる
トレースのメリット
サービス間での依存関係の把握がしやすいので、パフォーマンス低下や障害が発生した時の原因調査のスピード向上に繋がる

パッと見てどのサービスに障害が起きていているか把握しやすい(赤:5xx, 黄色:4xx, 緑: 成功)
トレースで登場する概念 (例 AWS X-Ray)

トレース(ルートスパン)・・・一つのリクエストで生成された全てのスパンの収集したもの
セグメント(スパン)・・・url, http method, status code, errorかどうか、応答時間、service名などの動作に関するデータ
サブセグメント(子スパン)・・・スパン内での呼び出しに関する詳細情報、sql、応答時間

トレースID・・・リクエストごとに生成されるID
セグメントID・・・(サブ)セグメントごとのID
トレースヘッダー・・・トレースID, セグメントID, サンプリングするかどうかの情報を持ったHTTPヘッダー(X-Amzn-Trace-Id: Root; Parent; Sampled)
トレースヘッダーを通して子セグメントに親セグメントのIDを持たせることでサービス間の追跡を可能にしている
サンプリングルール・・・トレースのしすぎでアプリケーションのパフォーマンスを落とさないようにするために、1秒ごとに最初の一つは必ずトレースしてそのあとは全体の5%などのルールを設ける ベストエフォート方式
インストルメント化・・・アプリケーションを計測できるようにすること
Headerの抽出と挿入、ライブラリをインストルメント化することで使用された関連値を含む設定されたspanで自動的にラップできるようになる
SDKのインストールのみで完了の自動インストルメントというものもある
トレースの設定方法

設定
ECS taskのiam、x-ray用vpc endpoint設定
アプリケーションコードのインストルメント化
aws x-ray agentやopentelemetry collector をサイドカーコンテナとして追加して、X-Rayへtraceデータを送信できるようにする
必要に応じてその他のserviceのx-ray設定を有効にする
データの流れ
SDKによってアプリケーションからセグメントデータがX-Rayデーモンに送られ、デーモンはバッファして定期的にデータをAPIへ転送する、APIでトレースを作成してconsoleで視覚化、分析を行う
コンソールでの分析
Service Map(CloudWatch ServiceLens有効化)

トレースデータを視覚化したもの
マイクロサービスが測定すべきメトリクスであるリクエスト数, error数, 応答時間(The RED Method)の確認
エラー内容や応答時間を選択し、フィルタリングされたtrace listの表示ができる
Analytics

特定のサービスに関連するトレースに対して、応答時間、時系列、http method等によりtrace listをフィルタリングしたり比較したりできる
トレースの要約の確認(status code別のtrace数の割合、応答時間など)
Trace List
トレースの集まりでtrace idをクリックすることで、セグメントのタイムラインや詳細を表示できる
想定される使い方

サービスの応答速度が遅い場合、service mapで障害やリクエスト数の急増がないか確認して、ない場合、トレースの表示から応答時間の遅いトレースをfilteringして、トレースの詳細へ移動し原因を調査する
deployの前後のパフォーマンスを比較したい場合、サービスマップでserviceを選択して、Analyticsで時系列別のトレースセット取得して応答時間と時系列の間に相関がないか調べ、あった場合トレースリストのトレースの詳細を確認
気になったこと
X-Ray-SDKではトレースとアプリケーションログの紐付けはJavaでしかサポートされていない 独自に実装する必要がありそう

対応できない場合、traceの詳細からlog insightへのリンクで移動しないといけない、またデフォルトで入力されるクエリのtraceIDを毎回消して検索しないといけない
まとめ
絶対に必要というわけではないが、パフォーマンス監視ができるようになったり、依存関係が複雑化してきたサービスの探索可能性の向上、平均修復時間(MTTR)の削減に繋がる可能性があったりとトレースは便利な機能であることがわかった。
DATADOGでは本番環境での常時接続型のProfilerでCPU やメモリーなどリソースを最も消費している関数 (またはコード行数)を明らかにすることができるらしく、Profilerも調べてみると面白そうだと感じた。
参考資料
https://docs.aws.amazon.com/xray/latest/devguide/aws-xray.html
https://newrelic.com/jp/blog/how-to-relic/metrics-events-logs-and-traces
https://www.datadoghq.com/ja/blog/datadog-continuous-profiler/
https://github.com/cncf/tag-observability/blob/main/whitepaper.md(3つの柱の画像)
https://d1.awsstatic.com/webinars/jp/pdf/services/20200526_BlackBelt_X-Ray.pdf(背景が黒の画像、3つの柱のトレースの説明の画像)
https://febc-yamamoto.hatenablog.jp/entry/2019/02/17/152014(The RED Method)
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/deploy_servicelens_xray.html(ログとトレースの紐付けサポート)