こんにちは、iimonでエンジニアをしている須藤です。 今回はRAGを試してみたいと思って調べていたところ、Difyというサービスを利用するとGUI上から簡単に構築できるらしいので、実際にRAGを利用したチャットボットを構築してみました
- Dify(ディファイ)の概要
- RAG(検索拡張生成)とは
- アプリケーションのタイプ
- ローカルで環境構築
- Notionの連携
- ナレッジの作成
- ChatBotの作成
- トラブルシューティング
- 公開
- ステップを分岐
- まとめ
- 参考
Dify(ディファイ)の概要
AI アプリケーションを構築するためのオープンソース LLM開発プラットフォーム
数百のモデルのサポート、GUI上で構築できる直感的なインターフェース、柔軟なフロー構成、高品質なRAGエンジン、堅牢なエージェントフレームワークが含まれていて、APIの公開やサイトへの埋め込み機能も提供している
RAG(検索拡張生成)とは
LLMの応答を作成する前にナレッジベースを検索し、リクエストの内容を拡張することで、モデルの再トレーニングなしで解答性能を向上させる技術
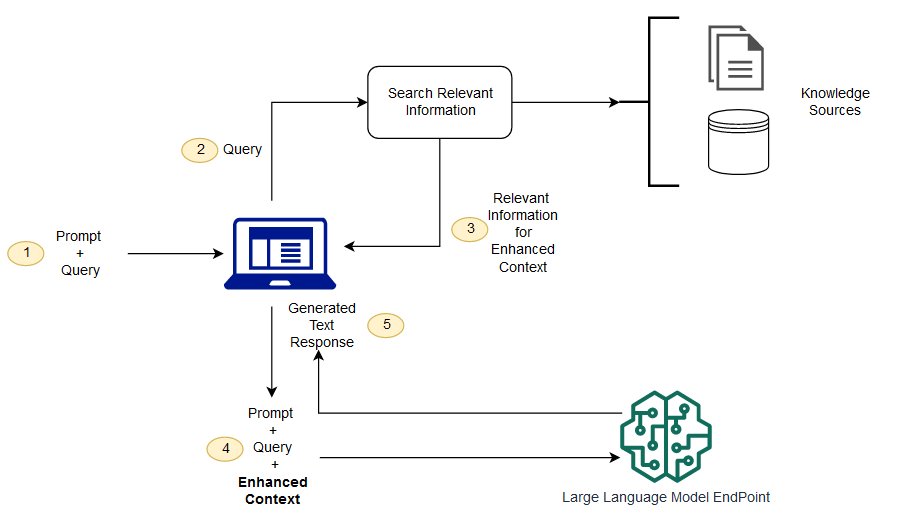
(https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html)
アプリケーションのタイプ
Difyで作成するアプリは主に4つのタイプに分かれていれています

チャットボット
過去の応答を踏まえた応答ができる (カスタマーサービス、複数のステップを含む論理的なシナリオなどに対応)
テキストジェネレーター
テキストの翻訳や要約、分類などの一度きりのテキスト生成タスク
エージェント
自律的に目標設定、タスク分解し、推論し、ツールを自動で呼び出す、対話型インテリジェント
ワークフロー
複雑なタスクを小さなステップに分解することで、タスクの自動化に対応する (メールの自動化、データ分析など)
その他特徴
エージェントは設定が少ない反面、LLMの推論能力への依存が大きい
ワークフローはタスクを小さなステップに分解して定義することで、LLMの推論能力やプロンプト技術への依存が少なくし、パフォーマンスや安定性などを高めることができ、またツールとして設定し、チャットやエージェント、ワークフローで利用することができる
ローカルで環境構築
コードをcloneして.envを作成し、docker composeを実行します
$ git clone git@github.com:langgenius/dify.git
$ cd docker
$ cp .env.example .env
$ docker compose up -d
http://localhost/installにアクセスすると管理者アカウントの設定画面が表示されるので登録します。
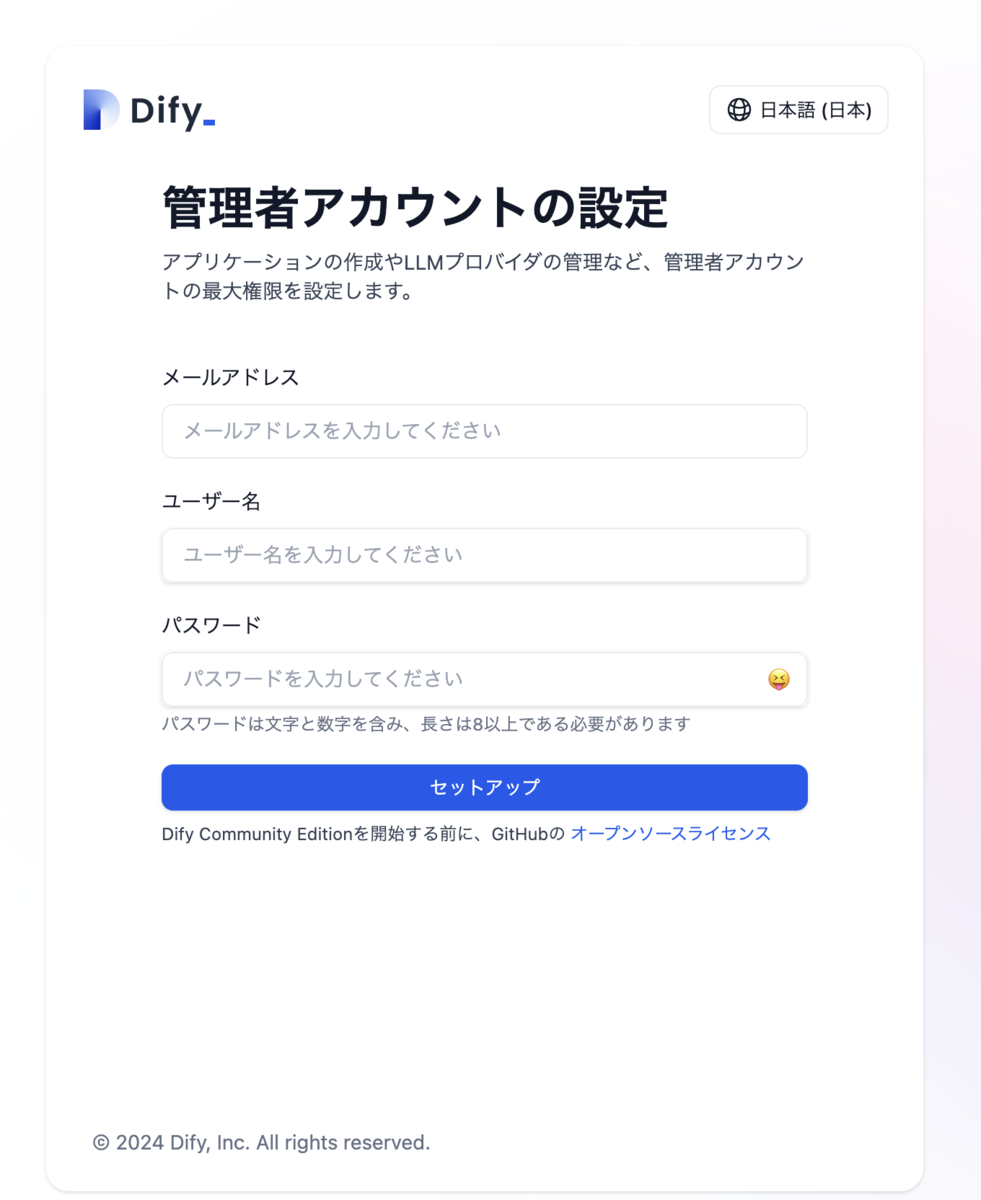
登録完了後、
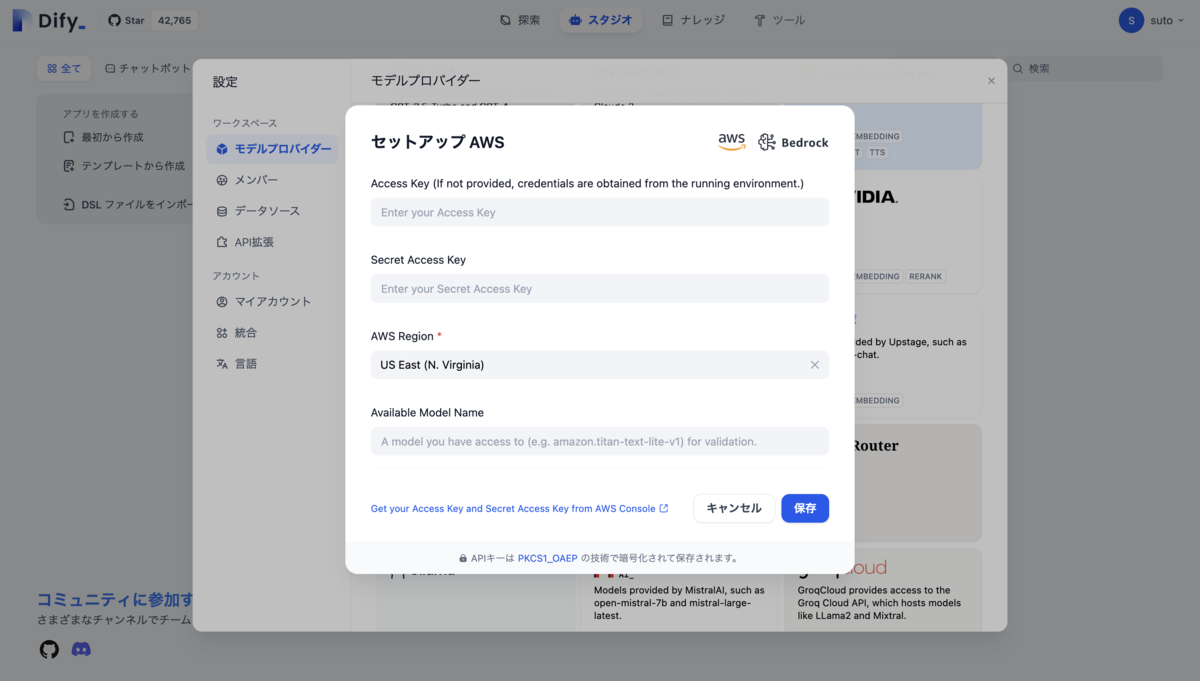
右上の設定>モデルプロバイダーから利用するモデルのセットアップとシステムモデルの設定を済ませます(今回はGemini 1.5 Flash, Titan Text G1 - Express, amazon.titan-embed-text-v1を追加)
Notionの連携
Notionと連携させて特定のページの内容をRAGのデータソースとして利用したいので、まずNotionの設定を行っていきます。
下記のurlからインテグレーションにアクセスし、新しいインテグレーションを作成します。
https://www.notion.so/profile/integrations
今回は内部インテグレーションで設定します。https://developers.notion.com/docs/authorization
作成後、内部インテグレーションシークレットを参照できるようになるのでコピーし、.envに
NOTION_INTEGRATION_TYPE=internal, NOTION_INTERNAL_SECRET=コピーしたシークレット
を設定
$ docker compose up -d を実行します。
Difyの設定>ワークスペース>データソース
でNotionが接続済みになっていることを確認できます
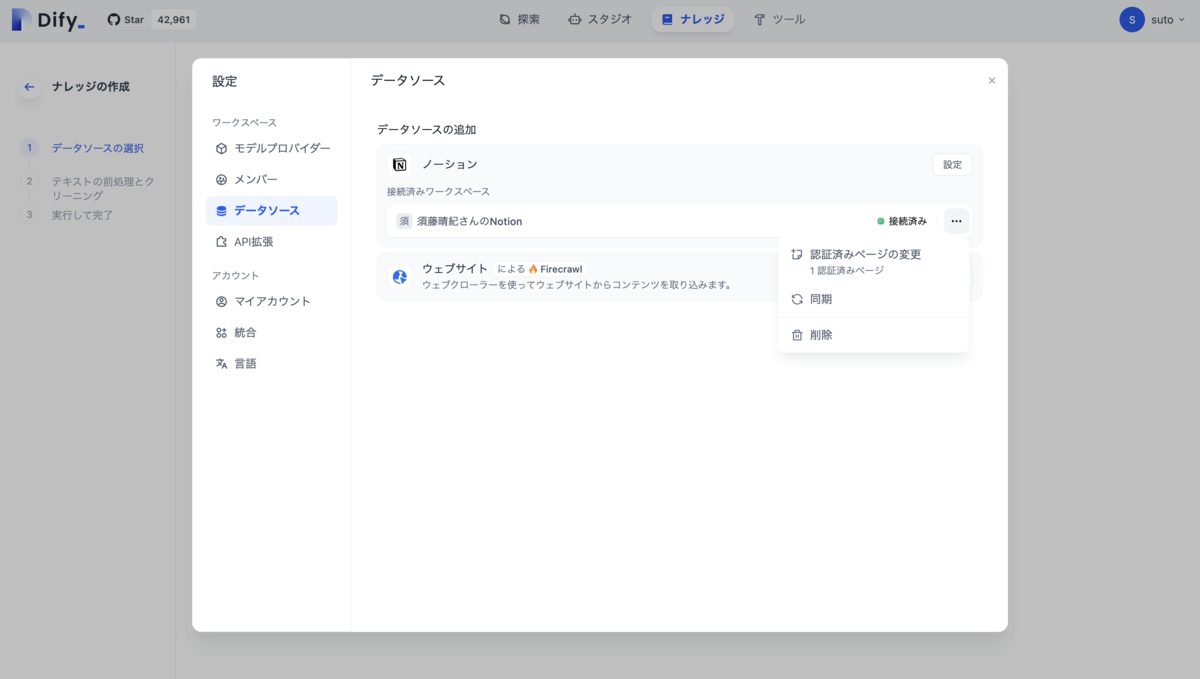
次に特定のページを接続できるようにするために
データソースにするNotionのページに移動して、右上の三点リーダーからコネクト>接続先をクリックすると先ほど作成したインテグレーションが表示されるので選択し接続します
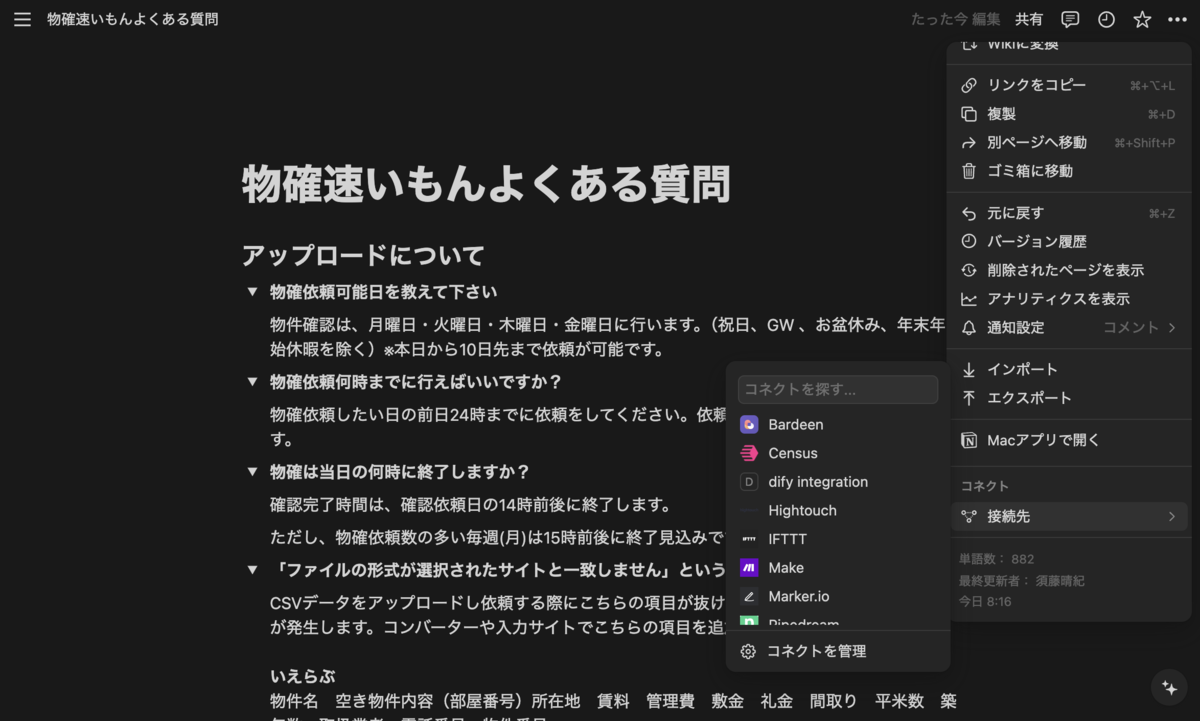
Difyの設定>ワークスペース>データソース>Notion>三点リーダー>同期をクリックしデータを同期させます
ナレッジの作成
ナレッジタブのナレッジを作成をクリックし、Notionから同期を選択すると同期されたページが表示されます。
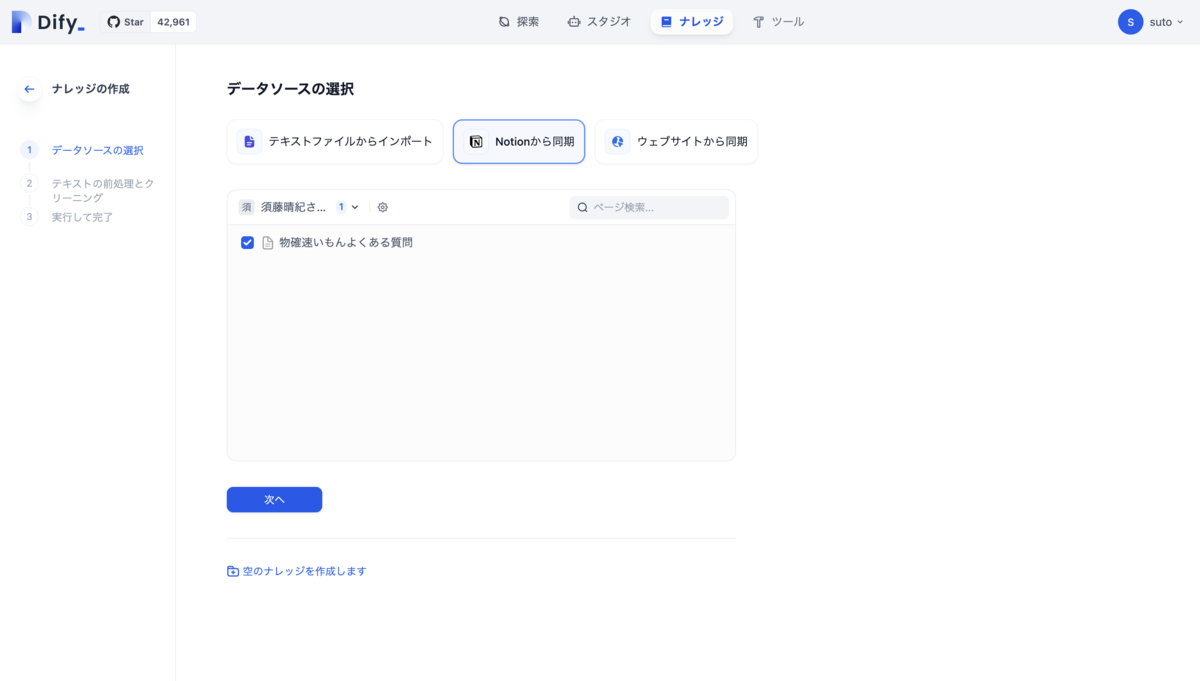
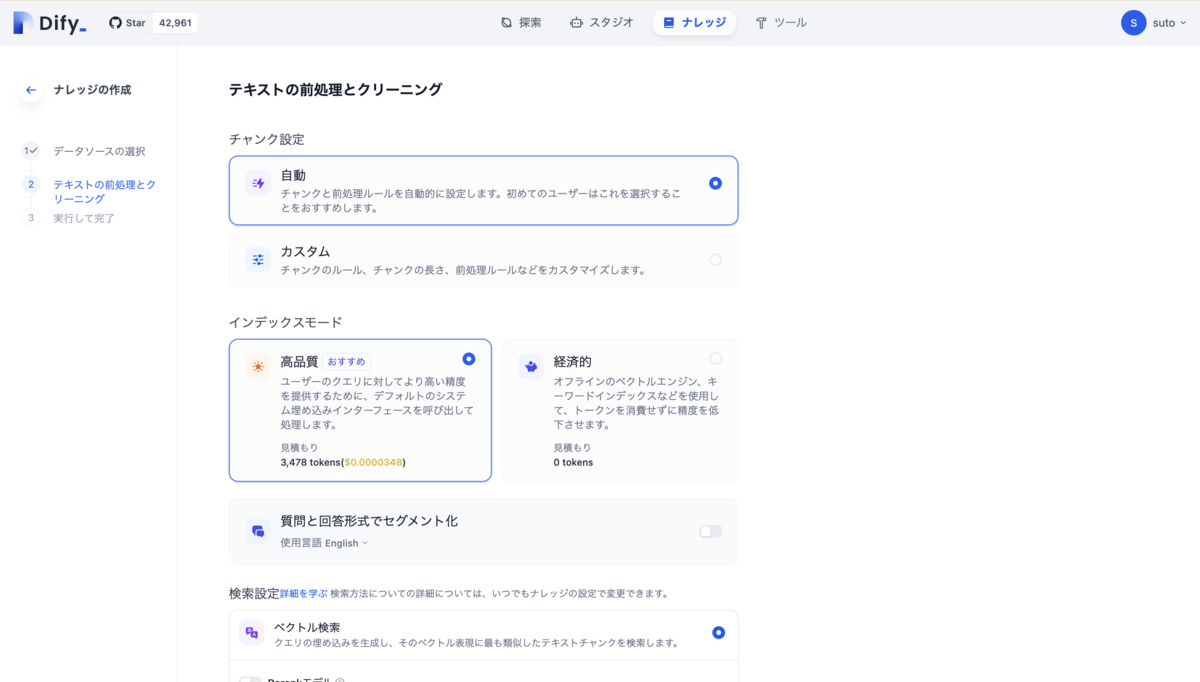
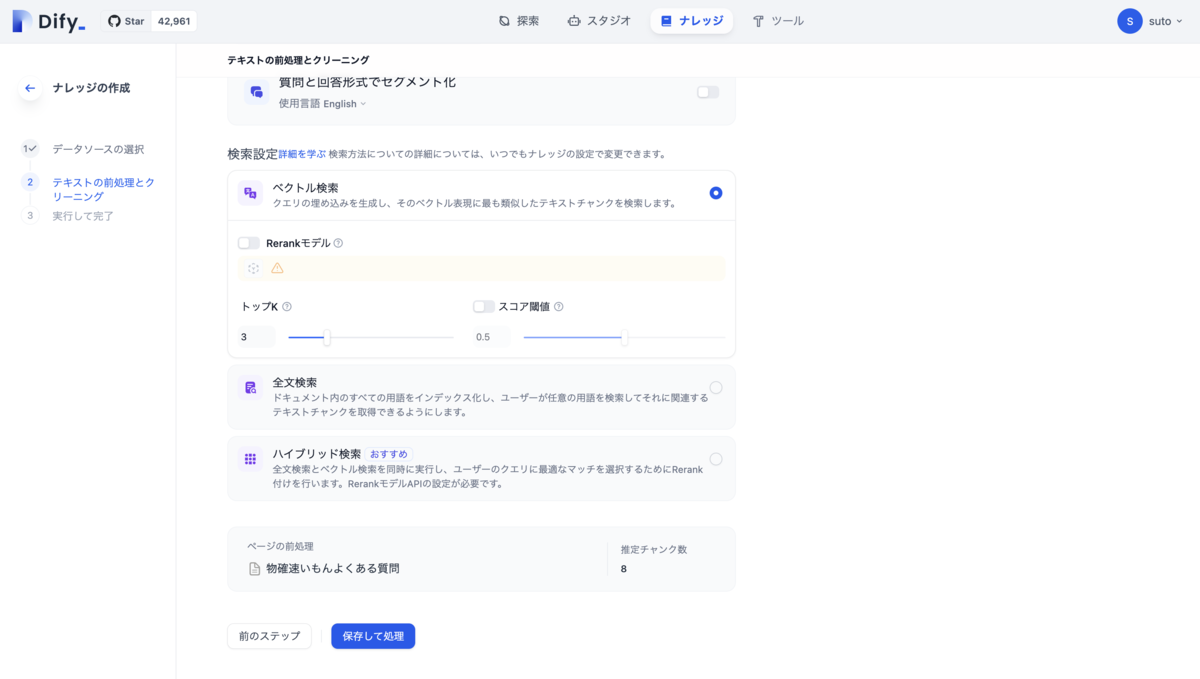
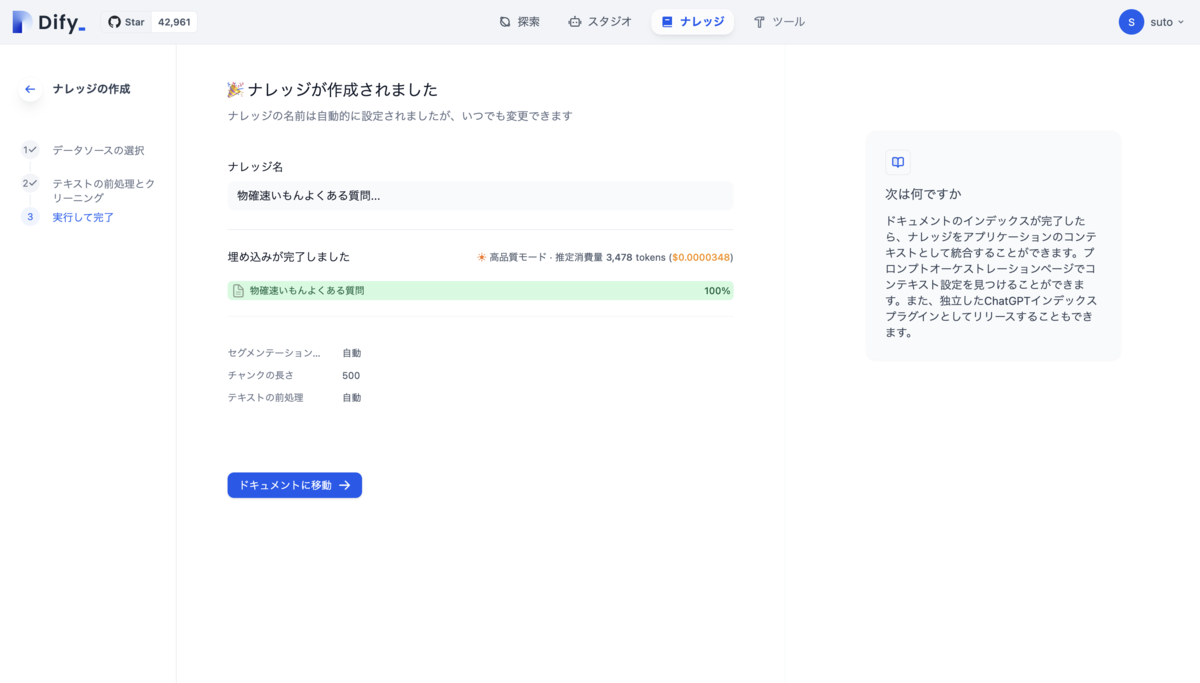
選択してテキストの前処理とクリーニングの設定画面に移動します、今回はチャンクと前処理ルールは自動的に設定し、インデックスモードは高品質、検索設定はベクトル検索に設定します、保存して処理をクリックするとナレッジの作成が完了します。
ChatBotの作成
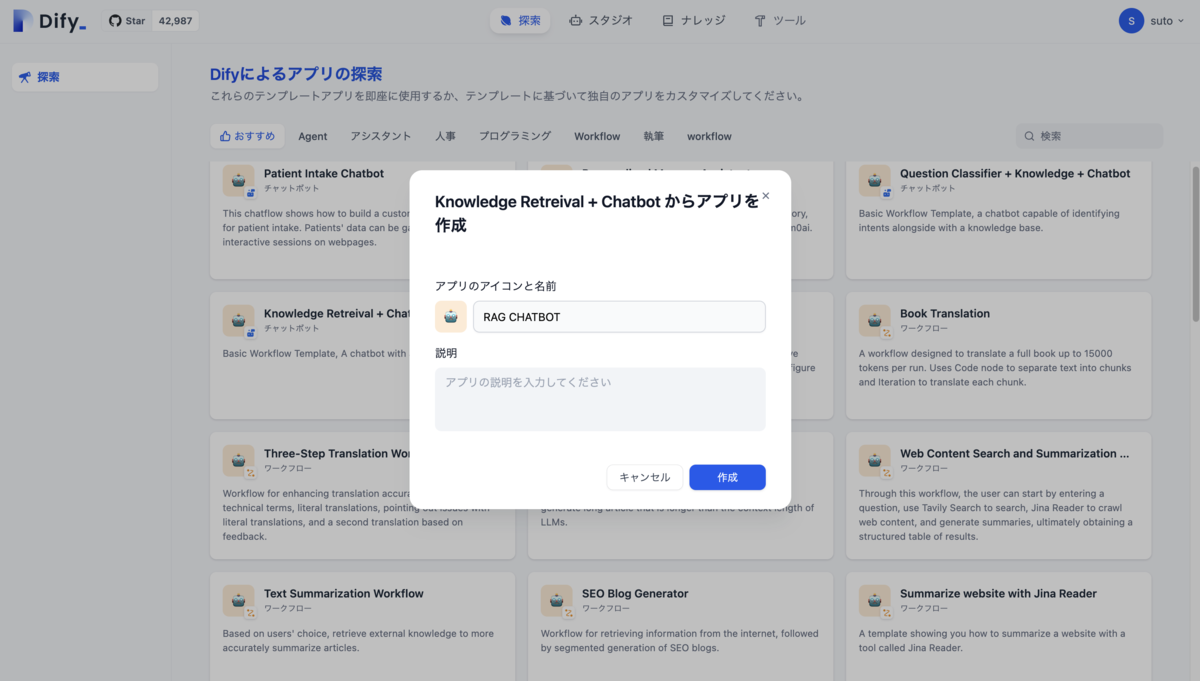
探索タブを見てみると、ナレッジを利用したchatbotのテンプレート(Knowledge Retreival + Chatbot)があったのでそれを選択します。
作成するとアプリケーションの編成ページへ移動し、視覚的にLLMの実行前にナレッジの取得の操作があることがわかります。
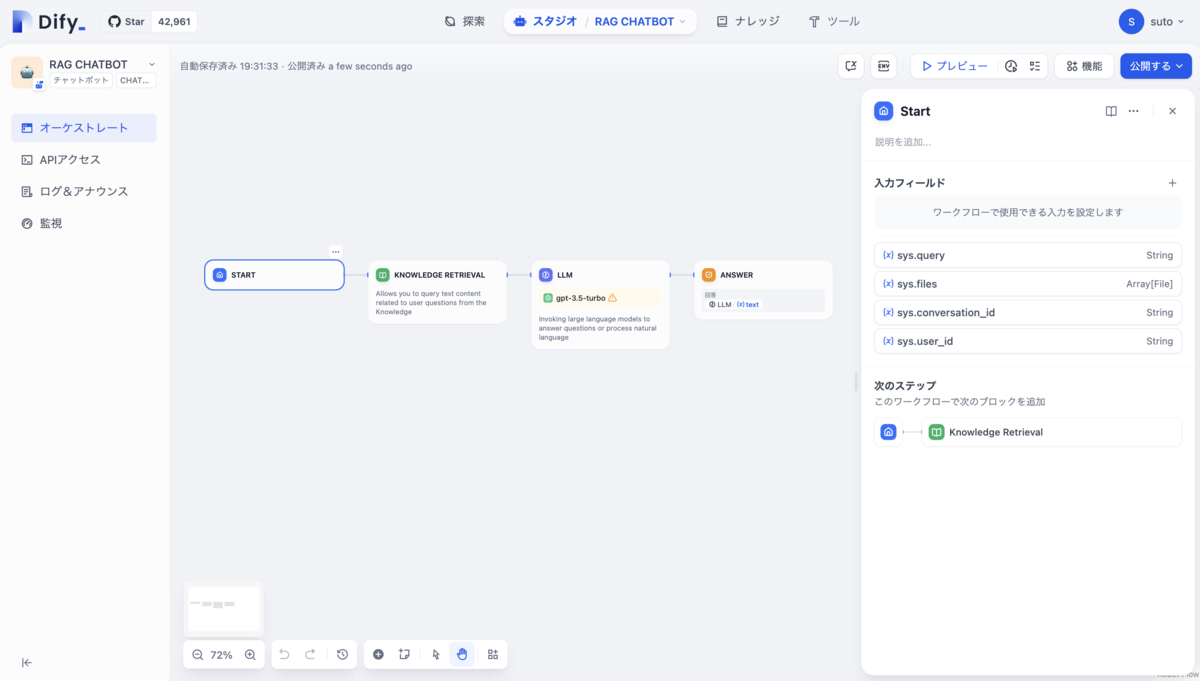
次に各ノードの設定を行っていきます。
ナレッジ検索ノードに先ほど作成したナレッジを設定し、
LLMノードのモデルを変更、RAGの出力結果をコンテキストに渡し、質問内容をUSERのメッセージとして追加します
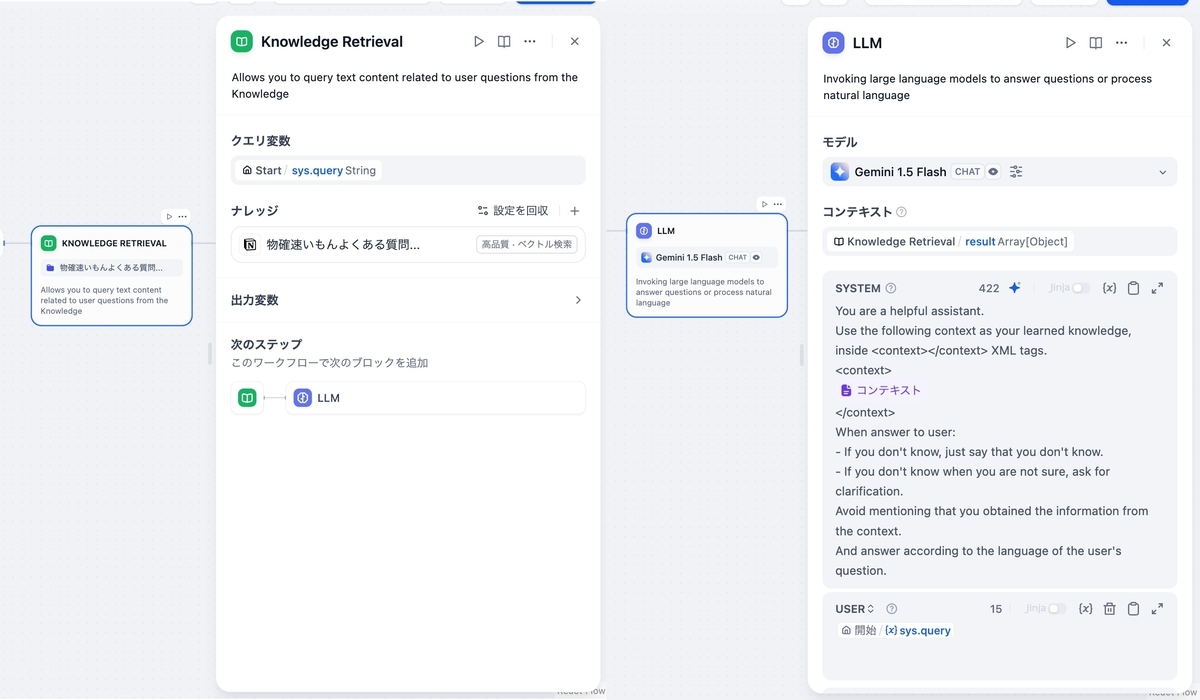
ここまで来たらあとは右上のプレビューから実行してみます。
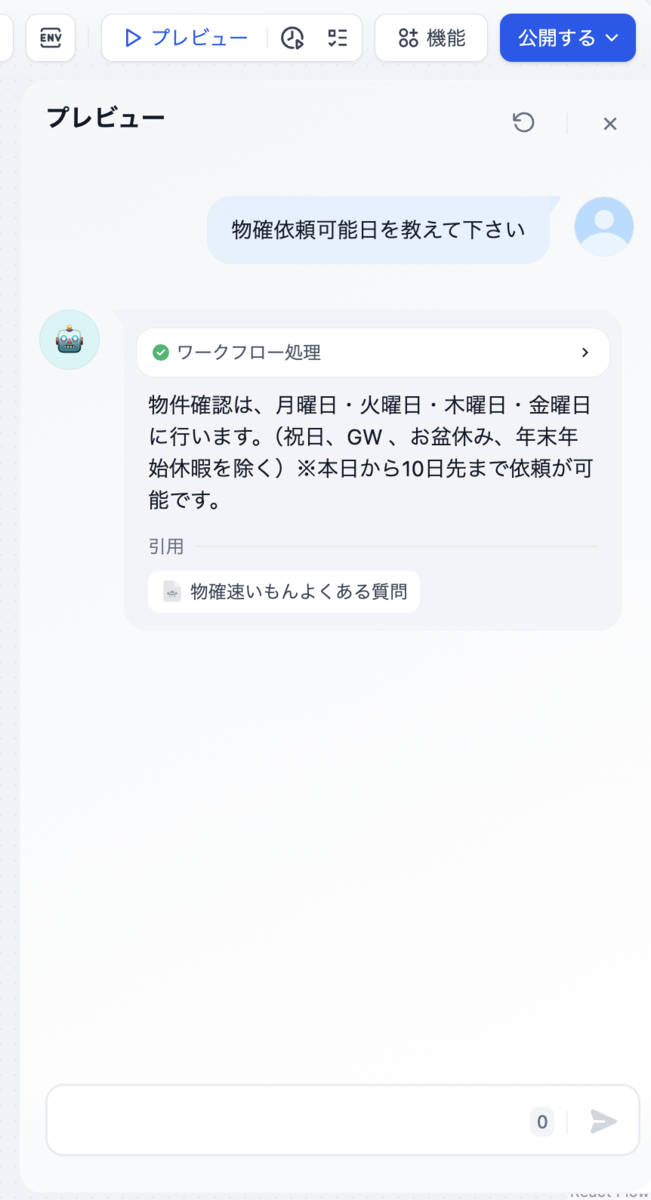
正しい答えが返ってきました。
トラブルシューティング
次にTitan Text G1 - Express(LLM)で実行してみたところ、全く正しくない答えが返ってきてしまいました。
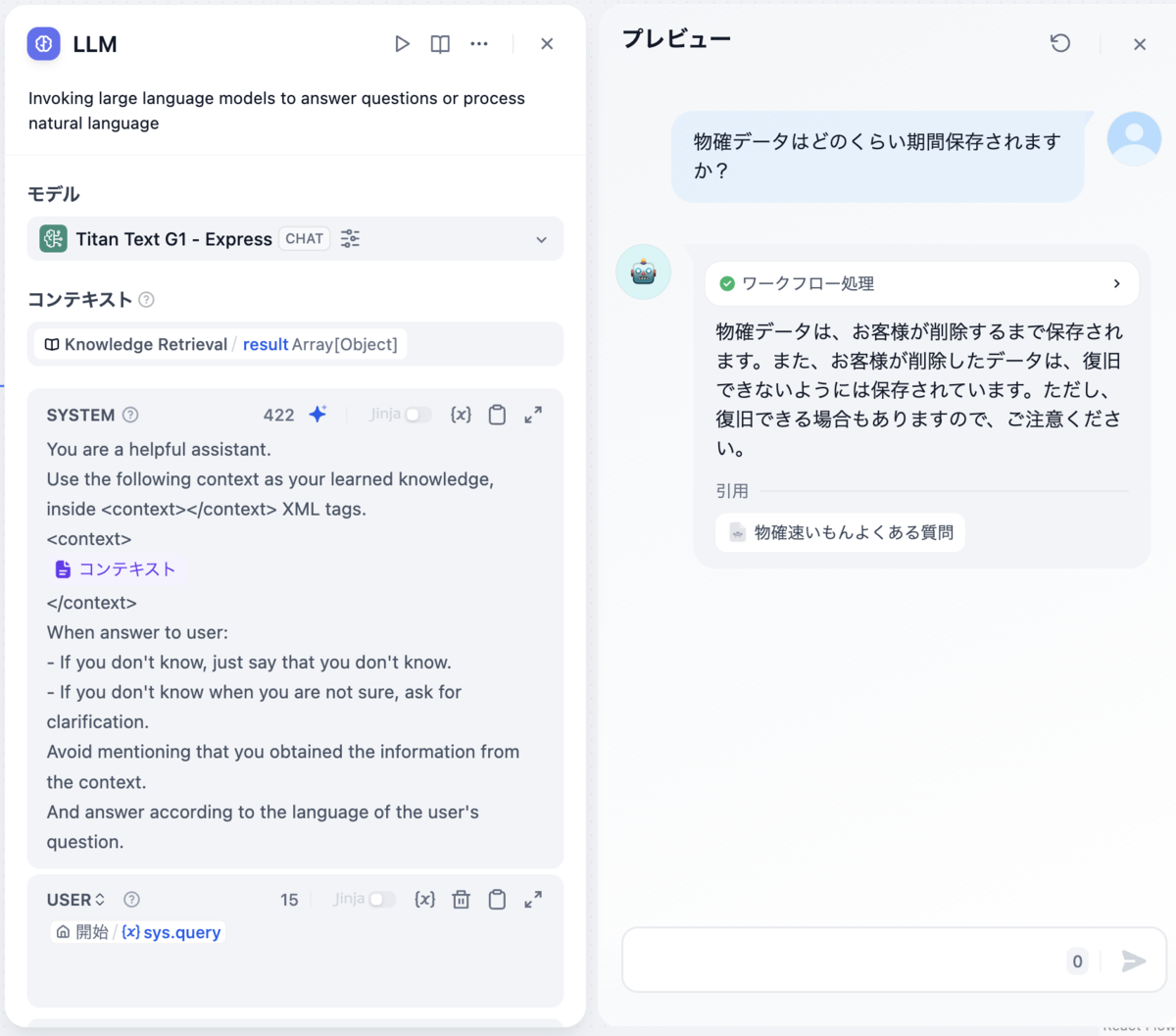
チャット応答の上部にあるワークフロー処理という部分からのナレッジ取得ノードの出力を確認すると情報は正確に取得できているようです。
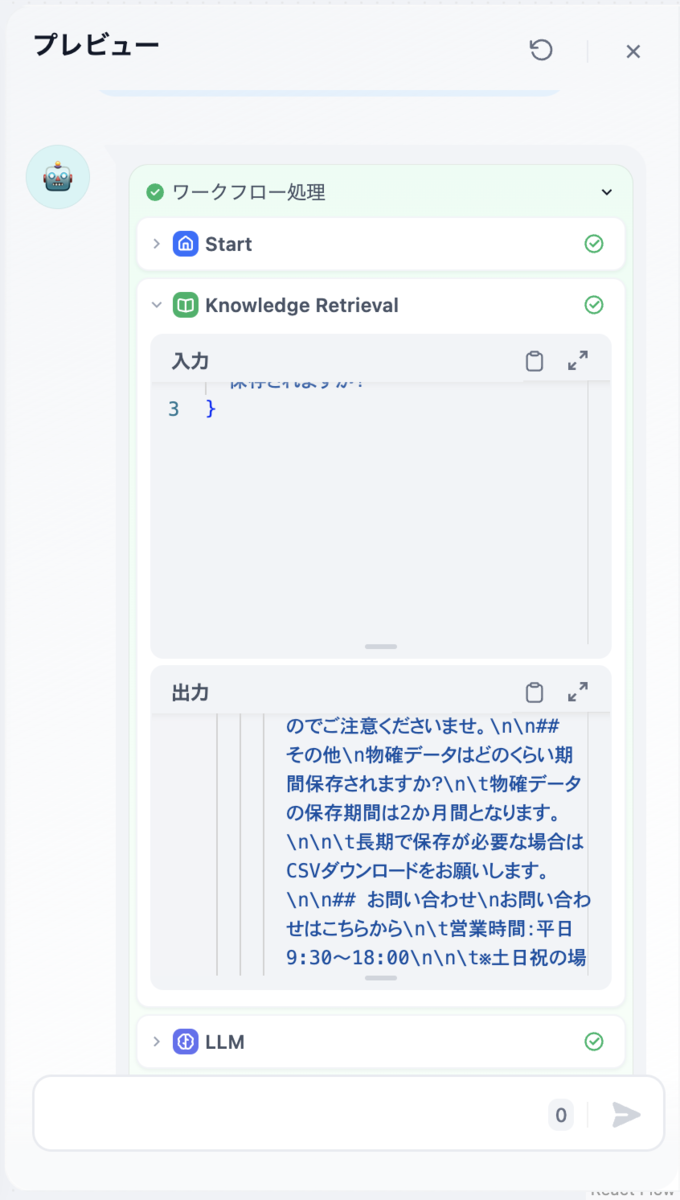
またノードの上部にある再生ボタンをクリックすると、ノード単位での実行(ステップデバッグ)ができ、実行が期待通りか繰り返しテストすることができます。
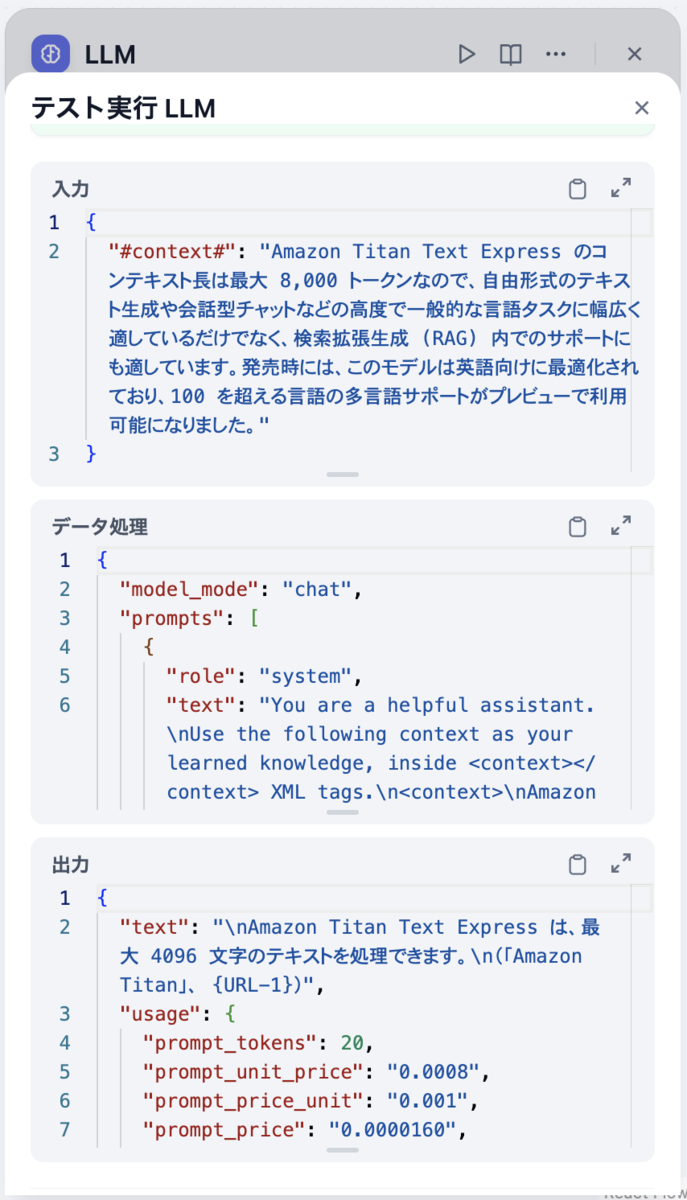
やはりうまく処理できていないことが確認できます
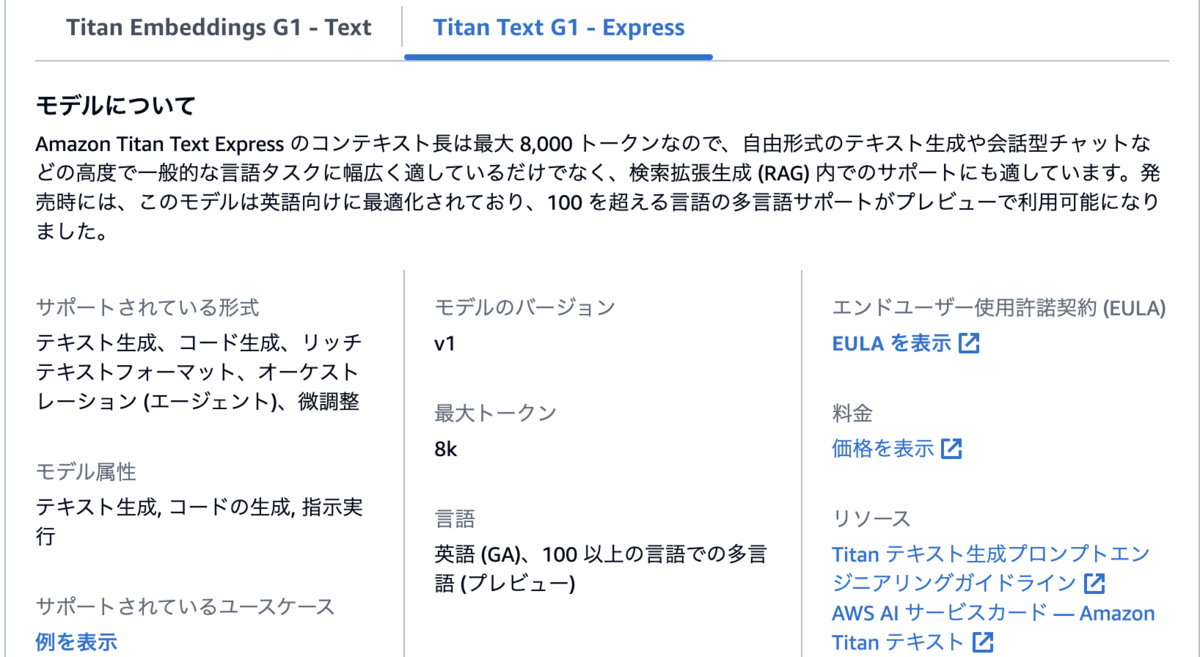
awsの説明ページを見たところTitan Text G1 - Expressは現時点(2024/08/27)では英語に最適化されていてその他の言語がプレビューなので日本語対応が弱いのが原因かと思われます。
公開
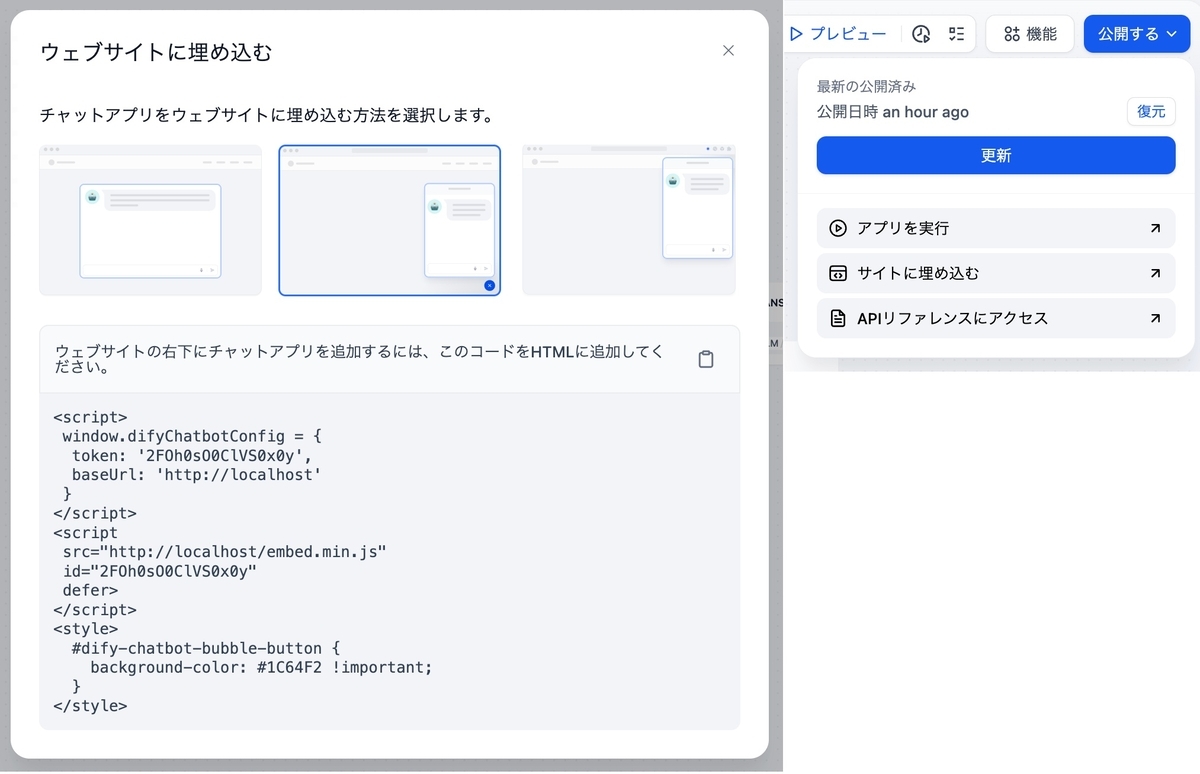
Geminiで動かせるようになったのでここで一度公開してみます。
ここまで構築するとすでに、APIや、サイトへの埋め込みを利用することができます。
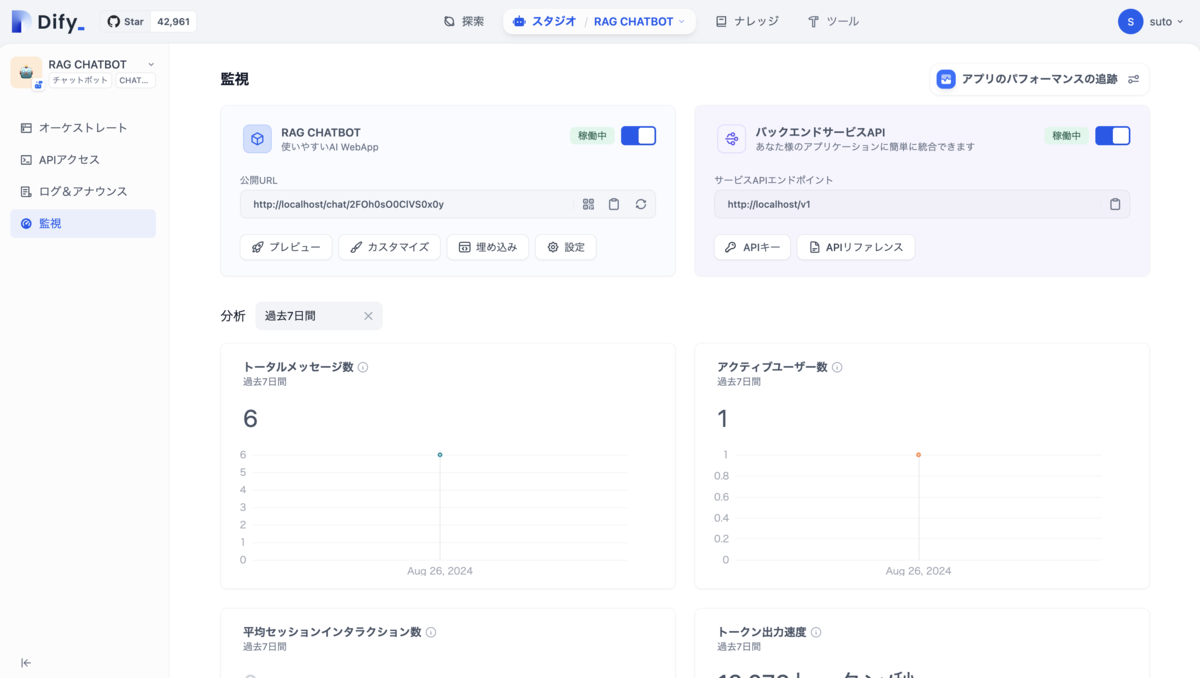
また、利用ログから会話の内容を確認したり、より高品質な回答をするために注釈として、質問に対する解答を用意しておくこともできます。
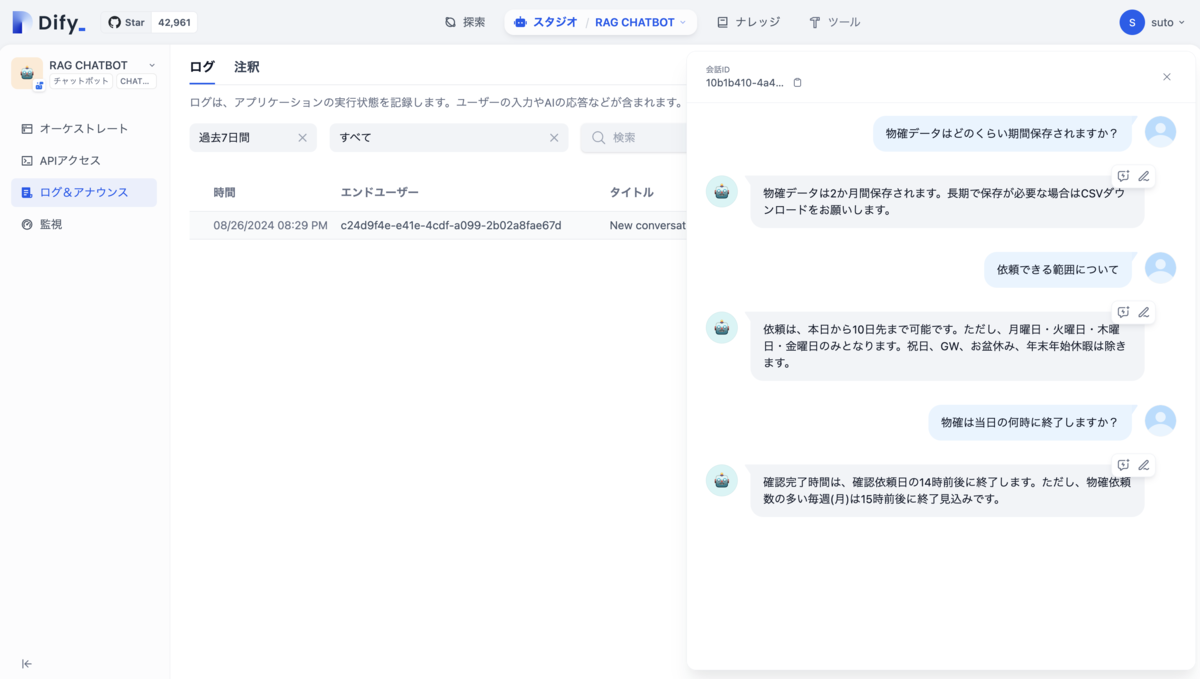
その他にもトークン出力速度、やトークン使用量などのメトリクスも見ることができるようです。
ステップを分岐
次に質問分類器という質問を分類するノードを利用して、処理毎に異なるステップを踏む構成に拡張してみます。
サービスの仕様に関する内容ならRAGを利用し, 採用関係ならapiの実行とそれを利用した固定の文章の出力、問い合わせならRAGのなしでLLMを実行して応答するように設定してみます。(本番利用は想定していません)
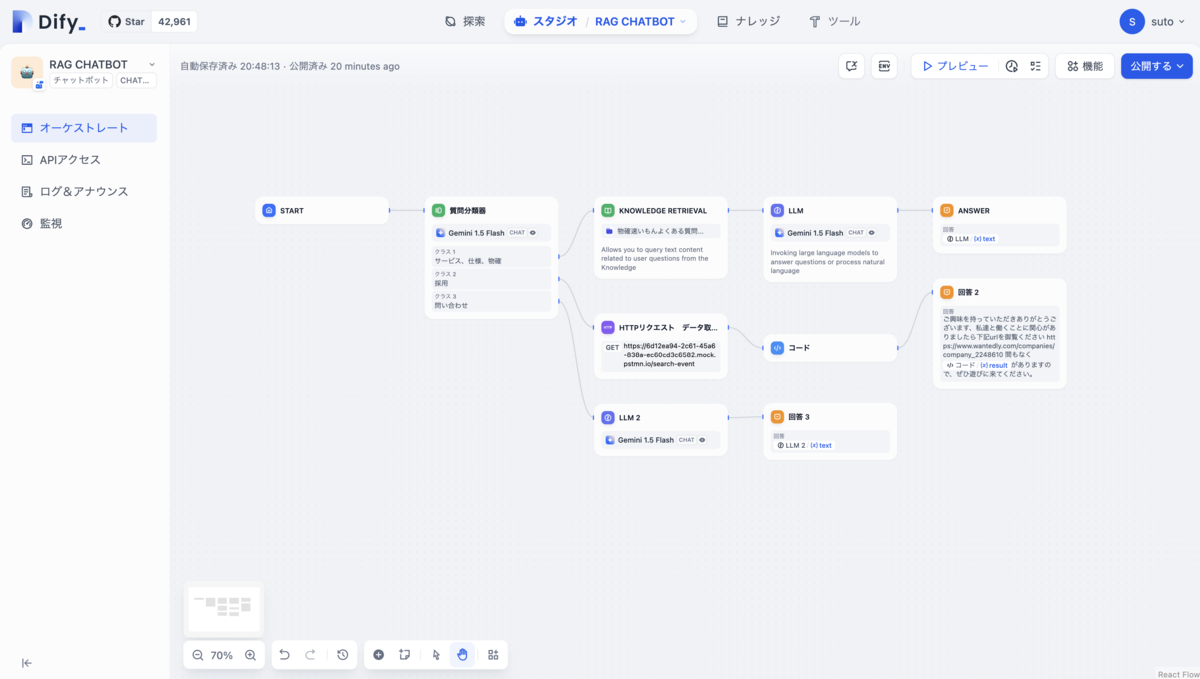
RAGの前に質問分類器を配置してそれぞれ後続のステップにノードを繋ぎ、動作確認をしてみます。一度デバッグモードで質問分類器だけ実行してみます。
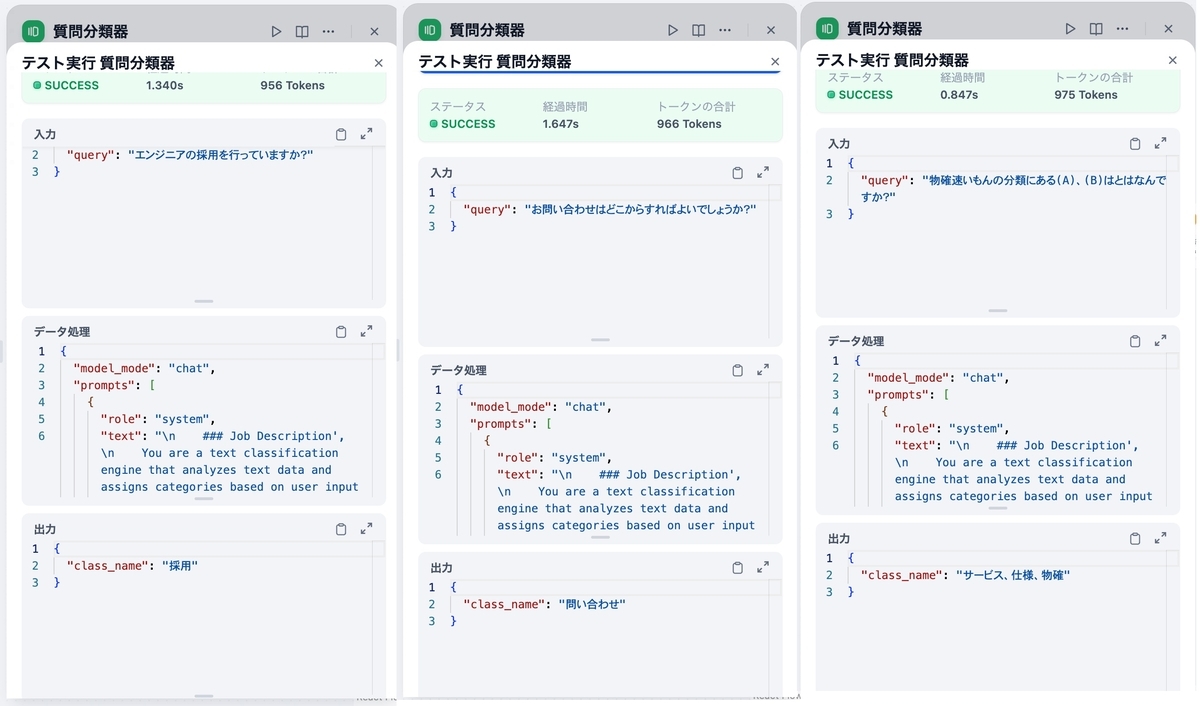
正常に分類されているので、全体を通して実行してみます。
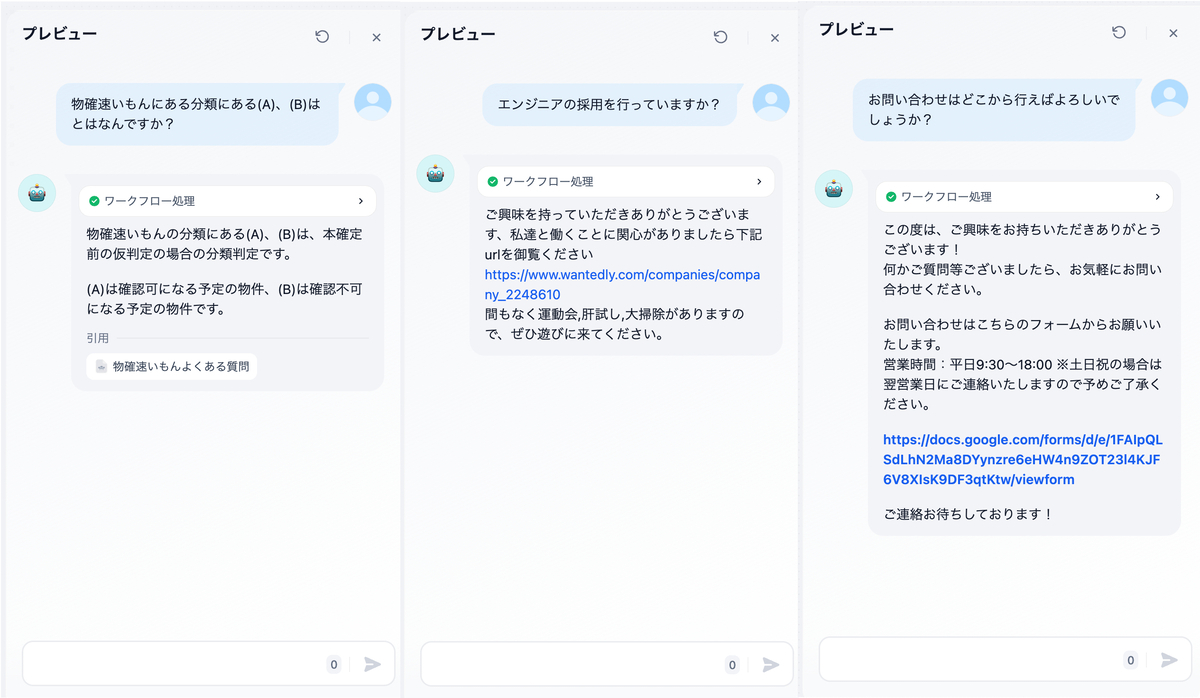
正常に応答できていることが確認できました。
また、質問分類器以外にもよく使われるコアノードがわかりやすくまとまったページがあるので見てみるとどのような処理を組み合わせることができるかイメージが付きやすいかもしれません
https://docs.dify.ai/v/ja-jp/guides/workflow/node
まとめ
今回利用した機能の他にも、ワークフローをツールとして定義し、チャットボット上で利用したり、はじめに質問例を表示したり、機密語リストを作りモデルの出力を安全にしたり(モデレーション)、DSLファイルで構成を共有できたりと様々な機能があるようです。
また、AIアプリケーションを作成したことのない私でも、ポチポチと押していくだけで直感的に構築できてアプリケーション作成のイメージを持つことができたので、非エンジニアでも社内のナレッジを利用した生成アプリケーションの作成ができるツールとして優れているなあと感じました。
今後は、langchainやrerank apiを使ってみたり、プロンプトのうまい作り方など学習してみると面白そうだなあと感じました。
参考
https://dify.ai/
https://github.com/langgenius/dify
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
https://acro-engineer.hatenablog.com/entry/2024/07/22/120000 面白そう
https://www.langchain.com/
弊社ではエンジニアを募集しております。
ぜひカジュアル面談でお話ししましょう!
ご興味ありましたら、ご応募ください!